
Lessons from the Cloud Bunker
Sunday, August 16, 2015
It’s been just over three years since I started working on building a fairly large cloud infrastructure at eBay. Our initial focus was to make infrastructure programmable and to enable agility through self-service APIs with some checks and balances for efficiency, security and availability. This model put infrastructure basics like compute, network and block/object storage in front of every developer at eBay. Though this allowed adoption of a wide variety workloads in our data centers, this journey also taught me a couple of very valuable lessons.
Don’t bet on ephemeral cloud abstractions
Ephemeral abstractions are things that fail. These may not recover from failures. The best example is a compute (e.g. a VM) with a local disk, an IP address and a hostname.
At the bottom of every public or private cloud stack diagram is the IaaS layer consisting of such ephemeral abstractions. Almost all IaaS layers implement a decade-old playbook from AWS. This playbook has three steps:
- Automate infrastructure abstractions like compute, block storage, and various network functions and offer APIs to manipulate those abstractions.
- Provide additional services for metrics, monitoring, orchestration etc.
- Expect users to put together a closed-loop automation layer using (1) and (2) to make their apps resilient to infrastructure failures.
As important and hard as steps (1) and (2) are, the basic flaw with this approach is that the amount of engineering it takes to implement step (3) is non-trivial. Very few get it right. Consequently, most users of these abstractions subject their apps to infrastructure failures and remain concerned about cloud not meeting their expectations.
Here is why.
In order to make apps resilient to failures at the bottom of the stack (which includes ephemeral abstractions), the user is expected to monitor and detect failures, and bring each app back to its desired state as quickly as possible. This is not an operational or even a dev-ops problem. This is a software engineering problem consisting of what we call at work as the closed-loop P-D-M-R cycle.
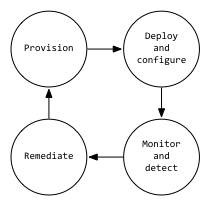
The steps in this closed loop are self-explanatory. Without the “monitor and detect”, and “remediate” phases, as infrastructure failures happen, apps drift from their desired state.
This playbook worked out well for those in the industry that understood this ephemeral nature, and then have invested engineering efforts to build software for step (3) above. For the rest, this playbook is a breeding ground for pets. Consumers of pets of course will want pet-friendly solutions like live-migration, VMs that run on shared storage, IP mobility, or their own “highly-available racks” (pun intended). This is a slippery slope.
Moreover, most cloud providers, including open-source cloud controller software like OpenStack, don’t even offer all the building blocks necessary to implement a closed loop P-D-M-R cycle. In those environments, remediation exercises tend to be human/ticket driven.
Here is the net lesson. Having things that fail as the primary interface to cloud may have been an acceptable cloud strategy in 2005, but not anymore.
The future is durable and declarative abstractions
It is time to think of cloud as a provider of durable cloud native abstractions that are resilient to failures. The term “cloud native” is fairly new with no clear definition. I would describe a cloud native abstraction as one with two fundamental characteristics:
- Durable: The abstraction may be built using ephemeral parts, but the abstraction itself is durable in the sense that it survives failure of its parts.
- Declarative: The user of the abstraction declares the desired state, and the service providing that abstraction attempts to maintain the abstraction in that desired state.
A virtual or a physical machine is neither durable nor cloud-native. Neither is a container. But a cluster of Kubernetes pods is a durable and declarative abstraction. To a lesser extent, a Marathon managed cluster of containers is also durable and declarative.
In the world of cloud native abstractions, you wouldn’t put together the P-D-M-R closed loop using the IaaS primitives. You would instead create durable abstractions that automate and shield you from having to deal with the complexities of the P-D-M-R cycle. You set a desired state when creating that abstraction, and the provider will try to maintain the desired state. The desired state could be as simple as the size of the cluster, or as sophisticated as some application KPIs.
Having closely dealt with infrastructure failures and the complexities of making applications resilient to such failures, I’m confident to say that the end of the era of ephemeral abstractions has finally begun. Durable and declarative cloud native abstractions are the future of cloud.
Does it mean that IaaS is dead? I don’t think so. You still need the ability to create parts (e.g. a VM or a network port or a block of storage) when creating durable abstractions, but most users of cloud shouldn’t have to deal with such operations. That layer will eventually become a pure provider-side internal layer.
Originally published at https://www.subbu.org/blog/2015/08/lessons-from-the-cloud-bunker.