
Why Learn from Incidents
Tuesday, December 17, 2019
Resiliency related discussions usually delve into so-called “resiliency practices” like circuit breakers, bulkheading, and timeouts, followed by monitoring gaps, then release safety practices, fault-containment patterns like sharding and redundancy, and even chaos testing. Sometimes, these discussions also digress into concepts like “auto-remediation” and “self-healing.” But what rarely happens though is any question of learning.
This absence of learning from incidents in such discussions is not surprising. The number of peoples that realized the role of learning from the success and failure of production systems in the IT industry is still small. For even the die-hard pager-warrior teams, “learning from incidents” is an esoteric concept. Safety is a relatively new topic in this industry.
Moreover, most work cultures want you to demonstrate bias for action and not “understanding” or “learning.” After your team recovers your system from a production incident, you’re often measured by how quickly you take the next steps, which include publishing a postmortem, determining action items, and finishing those quickly. “Wait, I’m learning” is not an expected answer. In our work cultures, we suppose learning to be automatic and implicit, and not something to talk about or explicitly do.
But why learn from incidents, or more generically, from working or failing production systems? Why is it relevant? Let me share a few reasons why, based on my personal experience.
First, learning from incidents helps close the gap between how you imagine the system to be working (the “as designed” state), and how it is working (the “as it is” state).
We use a variety of mental models to explain how complex production systems work. We form those mental models based on what we know about those systems. The inputs for these mental models include documented designs, code, configurations, metrics, monitoring charts and other artifacts. However, as our production systems undergo change, and as they age, our mental models become rustic and drift from reality. What was true about a system six months ago or even six days ago may not be true today.
Consequently, our understanding of the “as designed” state remains incomplete. Moreover, each person in the team may have a different understanding of the “as designed” state of the system. Team members use their incomplete understanding to make further changes, thus potentially compounding the gap.
Incidents allow you to validate or even dispute your assumptions about how you imagine the system to be working. There is no better way than to learn from incidents to validate or dispute assumptions and bridge silos of understanding. By walking away from an incident after restoration, you lose that opportunity.
In other words, incidents provide a feedback loop to correct and improve your understanding. Such improved understanding can help you improve the system.
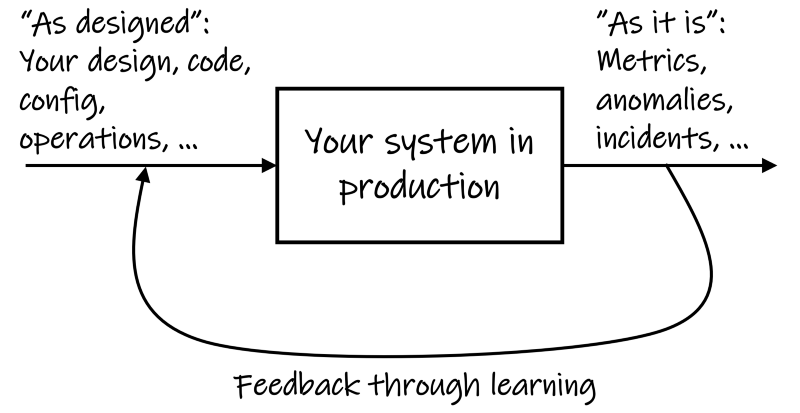
Not learning from incidents is like running production systems in an open loop with gut feelings and blind faith.
Second, learning from incidents grounds you into realizing that resilience is beyond a technology problem. Most of us routinely use terms like “resilience,” “robustness,” or even “self-healing,” and “auto-remediating” interchangeably. However, until you start to learn from incidents, you may not realize that people, processes, and culture are part of the system and play a vital role in keeping the system resilient.
As John Allspaw writes in Taking Human Performance Seriously, “the expertise and adaptive capacity of engineers is what keeps serious incidents from happening more often, and what keeps incidents from being more severe than they are.”
But how does this observation help improve systems that are currently falling over often?
When you’re dealing with such a system, you can’t just rush to using tech solutions alone. If you do, you might soon realize that your approaches are not working and that you must influence the culture first. Let me give you a couple of examples.
Imagine a work culture that insists on finding “the root cause” within a certain number of hours after an incident? Over time, teams in that culture get used to writing shallow postmortems to point to a “cause” so that they can move on to other work. The same happens in work cultures that insist on “five whys.”

Learning is non-linear, whereas the “five whys” approach makes you explore a linear sequence of events to find a purported cause. Instead, suppose you create a mechanism for the team to discuss what happened and what could have happened in an open format, they might walk away with a better understanding of how their system works, and what they could do to improve it.
Or imagine a work culture that uses a metric like “revenue loss” to measure the resilience of production systems. Teams in that culture get used to ignoring all other performance indicators as long as revenue loss is negligible. Consequently, they develop apathy towards issues that don’t result in revenue loss. Fixing such apathy then becomes a leadership challenge and not a technology challenge.
Though there is no cookbook for learning from incidents, recognize that it is a group learning activity. It involves sharing what you know, testing your assumptions, and adjusting approaches. Unlike individual learning, group learning allows for possibilities for critical thinking and exploration through dialog. Furthermore, it is not sufficient that the learning start and stop within the dev and operations teams. You also need leaders within the organization to foster the learning mindset for resilience.