
Studying an Incident
Monday, December 30, 2019
It is not often you get an opportunity to study an incident to illustrate a few lessons. A recent incident that I describe below teaches three key lessons:
- There are multiple perspectives on what happened and how to improve. The more complex the system is, the more perspectives you’re likely to discover.
- Asking for what went well and how things worked, instead of just asking about what went wrong, opens possibilities for improvements that you would otherwise miss.
- Resilience is what people do, and being resilient involves likely doing things you’ve not done before.
Below is an approximate representation of the incident timeline with certain notable events. I’ve omitted a few partially explored parallel paths.
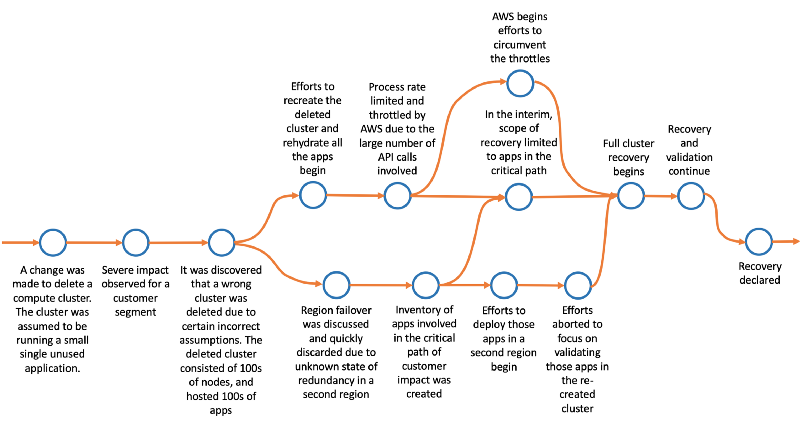
Multiple Perspectives
First, notice that there are at least four separate perspectives of this incident.
Team A that operates the shared compute cluster:
“We should have checked before deleting the cluster … We should avoid manual deletes like this … We should create smaller clusters to reduce the blast radius …We should chaos test this …”
Team B that owns the apps in the critical path:
“They (team A) did what? How could they? … Can we bring up these apps quickly in the second region? … Who knows the steps? … Who do we need to verify?”
Team C (external) that runs the throttled AWS services
“They (team A) did what? How could they? … How do we (recover from the throttle)? … What is the risk to other consumers of those APIs? …”
Team D that is orchestrating the events on the incident bridge:
“How is the rest of the site doing? What else went wrong? … Can we shift traffic to the other region? Why not? Have we tested this before? … Do we have a list of apps running on that cluster? … Who do we need to call?”
Such perspectives show that the narrative of the postmortem report can vary based on who is writing the postmortem. Collecting all these perspectives, reconstructing the incident, and identifying potential corrective actions, may take separate interviews with each group. A single live large gathering of all the parties involved in a post-incident review meeting may not uncover all these perspectives. A typical operational review with a senior titled person at the head of the table will undoubtedly miss most of these perspectives, and the discussion will most likely focus on what that person feels everyone should do.
What Went Wrong vs. What Went Well and How
A common practice of conducting incident postmortems to ask “what went wrong,” then a series of whys to find what that happened, and then identify future corrective actions to prevent such an incident from reoccurring.
Such an approach, in this example, will lead to the first event in the incident timeline, which is when an operator made a change to delete a compute cluster. Subsequent probing would discover that that the operator made an incorrect assumption, that the operator did not make sufficient attempts to verify that assumption, and that the change was not peer-reviewed.
Consequently, you would identify potential corrective actions like the following:
- Automating all deletes to include validation checks
- Peer-review of all manual changes
- Avoid creating large clusters to reduce the blast radius
- Chaos testing cluster rehydration
However, asking for “what went well and how” would uncover a different set of events and potential corrective actions.
Recall from the timeline that the deleted cluster was hosting 100s of applications, most of which were customer critical. But why was impact not broader than noticed? What protected the rest? This line of questioning would uncover the following:
- Most of those apps are redundantly deployed in a second region on a similar compute cluster in an active-active configuration.
- The traffic management layer automatically routed the traffic to those apps after the apps hosted on the deleted cluster became unavailable.
- The compute cluster in the second region scaled up automatically to support additional traffic.
- However, a few apps, including the ones found to be in the critical path of the impacted customer segment, were not redundantly deployed in the second region.
- The deployment system and the post-deployment configuration and validation checks were time-consuming, which prevented the quick deployment of those apps in the second region.
In other words, a certain amount of robustness was built into the architecture, which helped limit the impact.
You would then come up with a different set of action items from those identified in the “what went wrong” approach.
- Ensure that all critical apps are deployed in at least two regions. Q: How do we know what is critical?
- Identify all critical apps. Q: How do we keep it up to date?
- Periodically test automated failover between regions.
This example shows that probing for both “what went wrong” and “what went well and how” are essential. Each contributes to improving your understanding of the complexity of the system, how things work and identify potential corrective actions. Extending this line of thinking to all the perspectives listed in the previous section further enriches this understanding.
Resilience is What People do
Finally, this incident also illustrates that resilience is what people do. This incident involved opening up minds to alternative explanations, conducting parallel streams of analyses, adapting to new information as it emerged, and attempting things not done before. Each major component involved in this incident behaved as it was supposed to. Regardless, the system as a whole faced a catastrophe, and it took human coordination, quick thinking, and ingenuity to recover from the disaster. In fact, what is typical between incidents is how people come together to restore the system, with the rest being unique to each incident.
As John Allspaw says:
Though such a distinction between robustness and resilience seems nuanced and pedantic, understanding and appreciating the difference can lead to vastly different thinking, investments, and outcomes. For example, not recognizing this difference may limit you to only focus on software solutions like below.
- Improving observability, so you’re quick to know and learn about the dynamic behavior of the system.
- Building or adopting closed-loop automation systems — These are solutions that follow an act-observe-correct pattern in a closed-loop to automatically remediate components of a system when those are observed to be drifting from their desired state.
- Adopting cloud-managed services for their availability and more predictable behaviors, to replace do-it-yourself solutions.
- Reducing blast radius to contain faults and to minimize coupling with techniques like circuit breakers and fall-backs
- Traffic shifting and shedding for quick recovery
- Chaos testing the system by subjecting it to various failure hypotheses
These are all essential investments. But such steps alone will not let the overall system, which includes people, the tools they use, and the rituals they follow, build the capacity to adapt to changing conditions during a catastrophe and to learn from those conditions. You need to go beyond to include the following to build resilience.
- Understand how humans interact with the system and the assumptions they make when operating the system.
- Avoid language that prevents dialog and discovery during and after incidents.
- Move away from root cause hunting to understanding how the system works, improve your mental models for the system, and use that understanding to invest for the future.
- Ensure that people with titles are also learning. Most in such positions likely have dated understanding of how to build and operate complex production systems. However, since such people set the tone of the culture for their teams, it is vital for them to also learn in this process.
In Summary
For any company generating value from its production systems, complexity is a moat. Despite our attempts to shuffle the complexity through automated layers of abstractions, complexity is the natural state of real-world systems. Each layer we add and each change we make change our assumptions about how the system is supposed to work, and how it is actually working. Incidents provide an excellent opportunity to validate those assumptions and discover ways to improve. The practice of continuous learning from incidents must be an integral part of your operations-culture to build resiliency.
Thanks to Willie Wheeler for reviewing an earlier draft of this post.