
Forming Failure Hypothesis
Friday, September 27, 2019
Subjecting systems to failures is supposed to increase confidence in their stability. But why? How do you form useful failure hypotheses? How do you reason about their safety? Why should your organization listen to you and invest in testing your failure hypotheses?
I recently gave a couple of talks on this subject:
- “Safety in Chaos: Forming Realistic Failure Hypotheses” at Strange Loop 2019, St Louis, on Sep 13, 2019
- “Forming Failure Hypotheses” at Chaos Conf 2019, San Francisco, on Sep 26, 2019.
These talks summarize over two years of my quest to improve production stability at work. Through this time, I had to put aside some of my prior beliefs, learn from the constant chaos that our production environments are, and form new hypotheses. Slides and speaker notes are below.
The Setup

Chaos engineering has only been around in the information technology industry for just about ten years. In contrast, other areas like patient care, emergency response, space and aeronautics, manufacturing, industrial engineering, mining, etc., went through several centuries or decades of learning through disasters to incorporate processes and practices to promote safety.
This nascency is why we continue to hear about the rationale for chaos testing , the tools and techniques to practice this discipline, and occasional success stories. What we don’t hear about though, is that the road is rarely smooth, that chaos engineering programs don’t always work as expected, and often die after a while.
The gist of my talk is as follows.
- For your chaos engineering efforts to succeed, you must invest in learning from incidents.
- Chaos engineering programs that don’t consider learning from incidents will likely fail after initial enthusiasm and excitement.
- The need for and value of chaos engineering will fall in to place once you take the time to learn from incidents.
Slide 2: Slides and notes

You’re in the right place for the slides and notes. Look for other recent articles on this blog for more background material.
Slide 3: What is chaos engineering

Let’s take a brief look at this definition of chaos engineering.
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system’s capability to withstand turbulent conditions in production.
Chaos engineering is about making a calculated hypothesis about the system being able to withstand certain turbulent conditions. It is not about randomly killing servers or breaking other things. Some older descriptions of chaos engineering still refer to just doing those kinds of things.
Slide 4: A visual representation
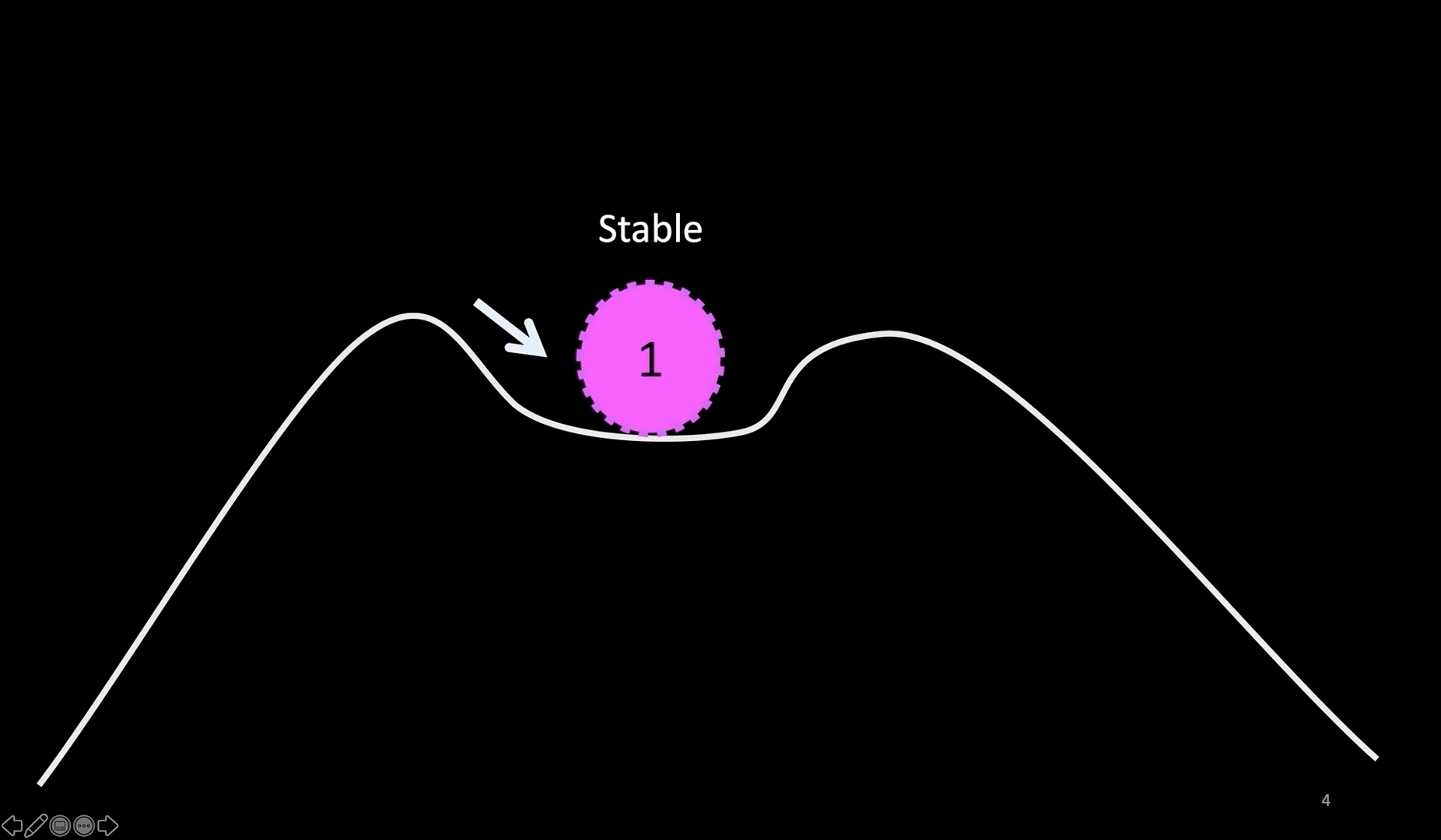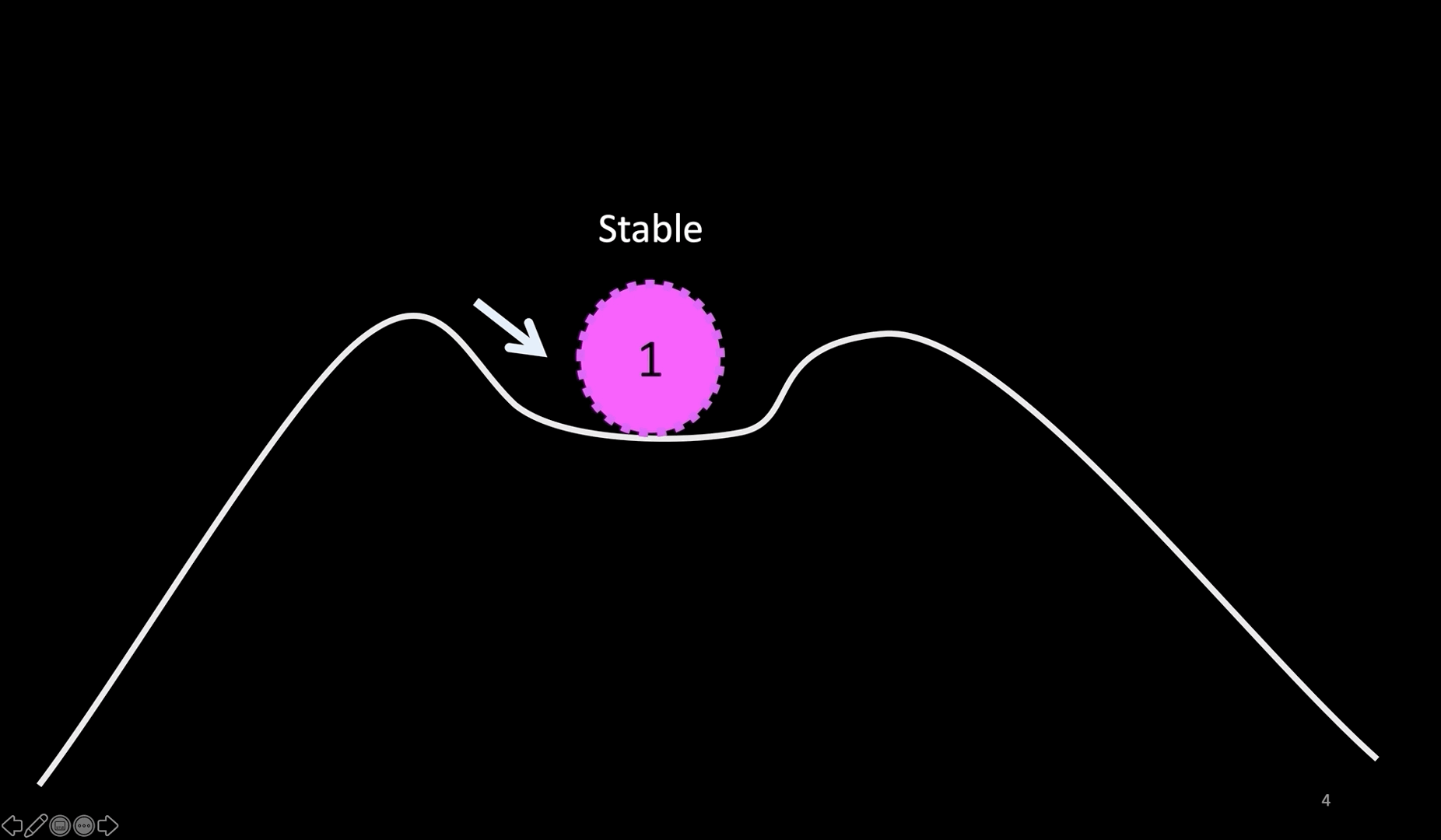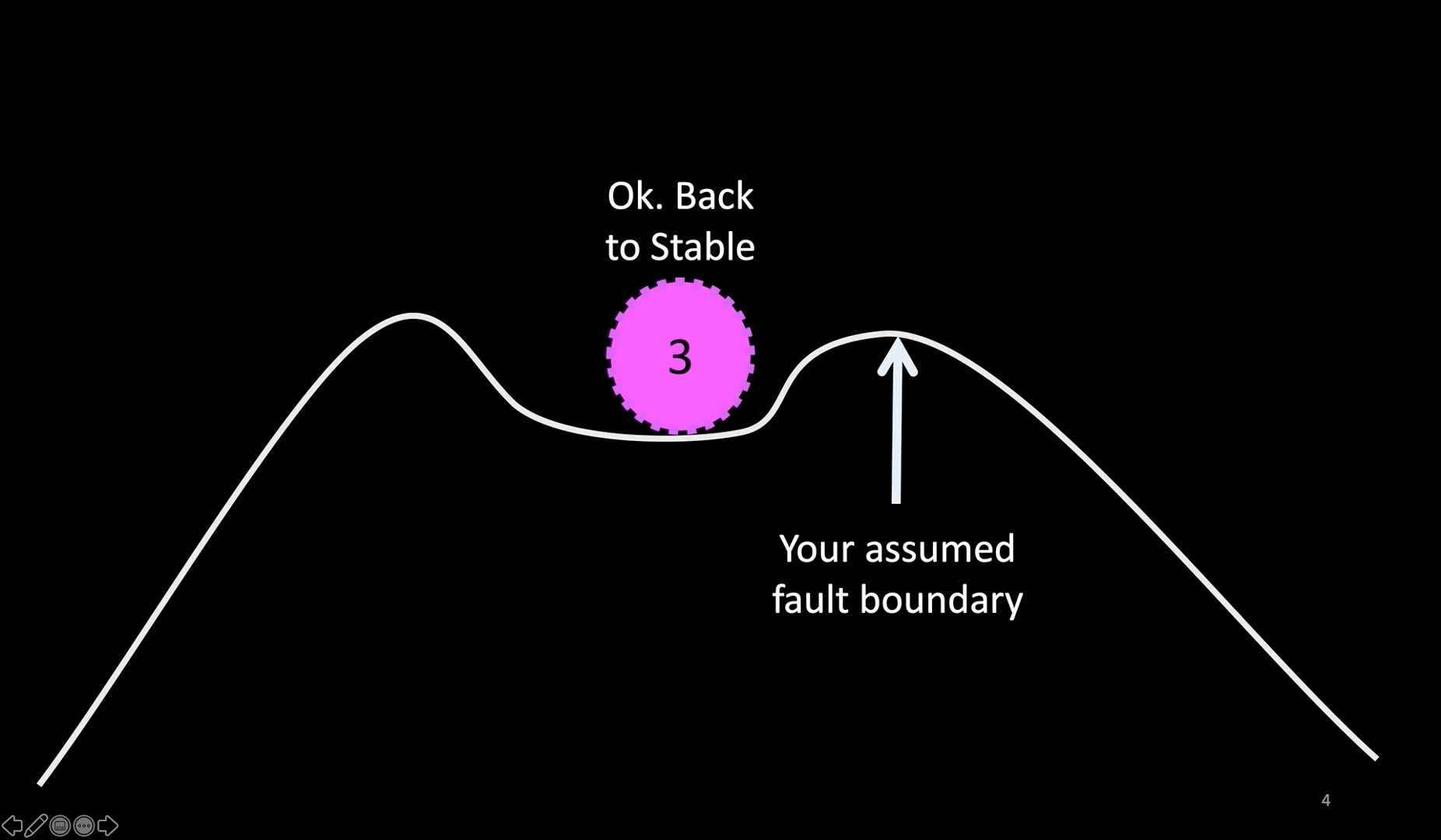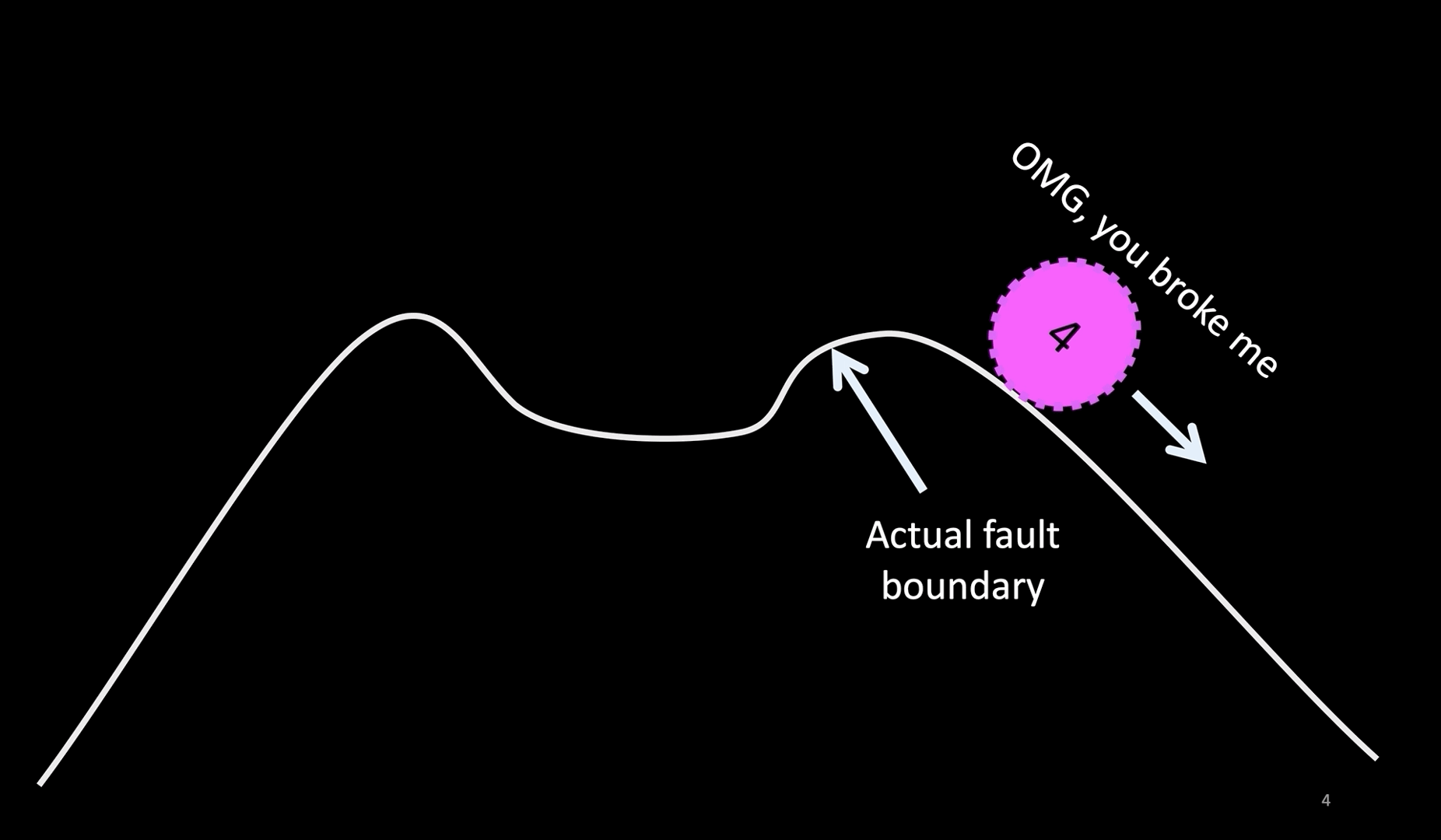
Here is an easier representation.
Imagine a system operating in a stable zone in the middle. You make a hypothesis that the system will continue to operate in that state even after you introduce a perturbation, like a server crash, hardware failure, or network degradation or even a network partition, as long as the perturbation does not push the system beyond the (assumed) fault boundary (shown by the upward arrow). You ensure that the system is not pushed beyond that boundary.
If the system returns to the stable condition, you proved your hypothesis. If, however, your assumption of the fault boundary is not valid, you may find that the system goes into the danger zone.
Slide 5: Questions to consider during this talk

As we get through the rest of this talk, keep the following questions in mind. We will answer some of these questions directly, and the rest indirectly.
First, what is the system? Is it the just software and config, the servers and the network, and the storage? Or, does it also include tools, processes, and culture that is used to build and operate the software, config, and the infrastructure?
Second, how do you form a chaos testing hypothesis? Do you copy what some else did? Do you just guess? Or do you come up with your own? If so, how?
Third, how do you ensure system safety? How do you guarantee that the test does not push the system from a stable steady-state into an unstable state that you cannot quickly isolate, and protect your customers from?
Fourth, why should anyone listen to you, and invest time and energy for chaos engineering? How do you justify the cost of this activity against all other priorities that your organization is pursuing?
Slide 6: Foray into chaos engineering

Here is how a typical journey to chaos engineering starts. You either start cloud adoption or at least some modernization through some of the latest and greatest tech for agility. You start breaking down monoliths and begin to adopt cloud-native technologies. Things seem to be going well with a lot of excitement in the air.
Slide 7: How to build resilience
Then reality hits you, and you start to deal with outages. You also encounter some cloud outages like the recent AWS AZ loss in us-east-1. You will discover that your automation has bugs, or that you’ve not automated everything well. You will find that your changes are also causing production issues. Then you start to think about resilience. How do you build resilience?
Slide 8: Enter chaos engineering
That’s when you discover chaos engineering. You research it. You read some books. You will find some tools to practice chaos engineering. It sounds fun and exciting. You roll up your sleeves and get down to work.
Slide 9: Not everyone likes you to attack their apps

When you approach teams in your organization that you’re going to subject their apps and services to chaos engineering tests, some teams will enthusiastically tell you to attack their apps.
You will come across some teams that will say “No way. Our stuff is mission-critical. Don’t bother us,” while others would say, “We’re busy now. We don’t have time for this. Come back in x months.”
Such reactions will compel you to exclude all those apps and services, and work only with the teams that enthusiastically support you.
Slide 10: Randomly killing servers only uncovers trivial issues only

Then you will discover that randomly killing servers only uncovers trivial issues. This is plausible given that the teams that are enthusiastic about chaos engineering have already invested in some basic robustness practices in their apps and services. Those that have not take such steps are not anyway participating.
Slide 11: You can’t/won’t test more serious failures

You also can’t and won’t try serious failures because you know those would get you into trouble. These could include blackholing your critical database, or breaking the network between two data centers.
Slide 12: Self-doubt

The outcome — you become frustrated. You start to doubt yourself. You start to think that you or your company is not competent enough to adopt chaos engineering when every other company seems to be doing chaos testing all the time!
Slide 13: Valley of despair

That’s how you get into the valley of despair. Your chaos engineering program is likely to die at this point.
I faced this situation about a year and a half ago. How do you get out of this valley?
Slide 14: Null Hypothesis

For the sake of discussion, let’s consider a hypothesis that “chaos engineering has nothing to do with a system’s capability to withstand turbulent conditions in production.”
Starting with such a hypothesis lets you discover if, why, and when chaos engineering might help.
More importantly, some of the pioneers in the industry that discovered the need for chaos engineering, and incorporated this discipline into their org culture, went through a journey of self-learning and discovery. Starting with a null hypothesis might help you go through a similar discovery process but within the context of your production systems, your tools, and your org culture.
Slide 15: How is the system behaving in production today?

To start with this null hypothesis, let’s set aside the question of making the system withstand turbulent conditions. Let’s instead ask how the system is behaving in production today.
Slide 16: “as designed” vs. “as it is”

How do you check how is the system behaving in production today?
You can start with the “as designed” state. Your documents, diagrams, and even code give you an indication of how the system is designed and intended to work, but not as it is working in production today. Furthermore, even the metrics we measure, logs we collect, and the alerts to setup represent the as “designed state“:” and not the “as it is” state. In other words, the “as designed” state is biased by your expectation of how the system is supposed to work, but not how it is working today. The “as designed” state is as nothing but an imaginary state. It is an approximation, not real. It remains incomplete as the system complexity increases.
The “as it is” state, on the other hand, is complex. We don’t fully understand and can explain all parts of it. We can’t fully explain why it works when it works, or why it is not working when it is not working. When it fails, we struggle to explain why. We use war metaphors to conduct incident procedures.
Unlike docs, diagrams, code, logs, metrics, etc., incidents tell us about the “as it is” state of a system.
Slide 17: Learn from Incidents

That’s exactly what I did when I entered the valley of despair. I studied incidents.
See my prior blog post Incidents — Trends from the Trenches, and slides of my OSCON 2019 talk If Only Production Incidents Could Speak for more details of my approach and findings. In this talk, I’m going to share a few highlights.
Slide 18: Changes are contributing to a majority of the impact
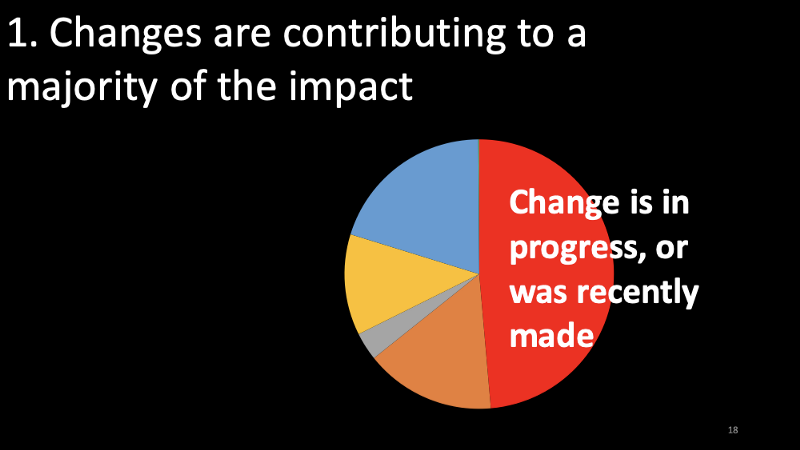
My first observation is that changes are contributing to a majority of the impact. In addition to the references from the previous slide, also see Taming the Rate of Change.
Slide 19: Second and higher-order effects are hard to troubleshoot

The second observation is that, due to the mixed nature of our production environments with fast-changing and slow-changing services, as well as monoliths and micro-services and tech debt, it is getting hard to reason about second and higher-order effects of changes and failures.
Slide 20: Unclear fault lines

My third observation is that the fault boundaries (or “blast radius” of failures) are unclear. Often, the “as designed” state does not include the intention of fault boundaries. When they exist in the design, they remain untrustworthy.
I’ve witnessed incidents where a change or issue in one part of a system impacted an unsuspecting another part of the system surprising many people on incident bridges. I’ve witnessed incidents where hundreds of millions of dollars of investments in supposedly redundant data centers in different locations could not empower incident commander to make a decision to shift traffic away from a data center outage due to a power failure, all because the incident commander could not determine if it is safe to shift traffic due to some unknown interdependencies between those data centers.
Slide 21: Actions

What do these findings motivate you to do?
First, improve release safety through progressive delivery of changes, so that you are safely introducing changes into production.
Second, ensure tighter fault domain boundaries in the “as designed” sate. That is, be explicit and intentional in your design about fault domain boundaries.
Third, implement safety in the “as designed” state. This involves implementing not only fault domains but also other robustness techniques like being able to shed or shift traffic, failovers, fallbacks, circuit breakers, etc.
And then, determine what failures to test in production. In particular, the second and third activities above will allow you to increase the severity of your tests and help you discover the “as it is” state. You can’t test your hypothesis unless you account for such safety conditions in the “as designed” state of your system.
Slide 22: Reflecting on my findings

As I reflect on my approach incident analysis, what I find most rewarding is the act of learning from incidents. The discovery of the patterns like those I shared in previous slides are interesting and relevant, but not as much as the act of learning from incidents itself.
This journey made me realize the importance of learning from incidents. Incidents tell us about the “as it is” state, and listening to incidents leads us to discover chaos engineering. It makes you realize that chaos engineering would prepare you architecture, tools, processes, and culture to be resilient to failures.
Slide 23: But how to prioritize such work?

How do you prioritize such work? How do you convince various decision-makers at your organization to invest time and resources for chaos engineering?
First, pick the most critical areas to get the most value of your investments into this kind of work. This is because not every system brings in the same value. Pick the ones that are most important, and worth protecting in your organization.
Second, learn to articulate value. Don’t let anxiety drive the conversation. Most organizations start to rally troupes after major incidents to invest in hygiene activities like chaos engineering. However, such approaches may not always be sustainable.
I will give you an example. Last year, some of us were in a room debating whether to invest in deploying a critical part of our stack in a second region and invest in testing for failover between two regions. Some of us in the room were arguing for such an approach as, in our minds, it was the right thing to do. The rest in the room argued that doing so would cost more money, and more importantly adds a few months to the project timeline. That group wanted to defer the second region investments to a future date.
Ultimately what settled the debate was the back-of-the-napkin calculation by one of our teammates. With a few calculations, he pulled up an approximate per-minute revenue driven by that part of the system and asked how much downtime we can afford. We debated on whether an hour, or two hours, or 15 minutes, or 30 minutes is okay. Finally, most in the agreed that we should not go beyond 15 minutes, and agreed that we’re unlikely to hit that 15-minute mark without investing in a second region and practicing failover. Debate settled.
In this example, the value is a dollar number. But it does not have to be the case. Depending on your situation, pick a value indicator that reflects one of speed, quality, or cost. Most businesses and stakeholders are interested in being “faster, better, and cheaper.” Appeal to those when formulating value-based arguments.
Also, realize that not every part of the system may need to have the same robustness. Certain amounts of losses may be acceptable for some parts of your system. Tailor your investments accordingly.
Slide 24: Journey out of the valley of misery
Given this, how do you get out of the valley of despair?
First, learn from incidents.
Slide 25: And then
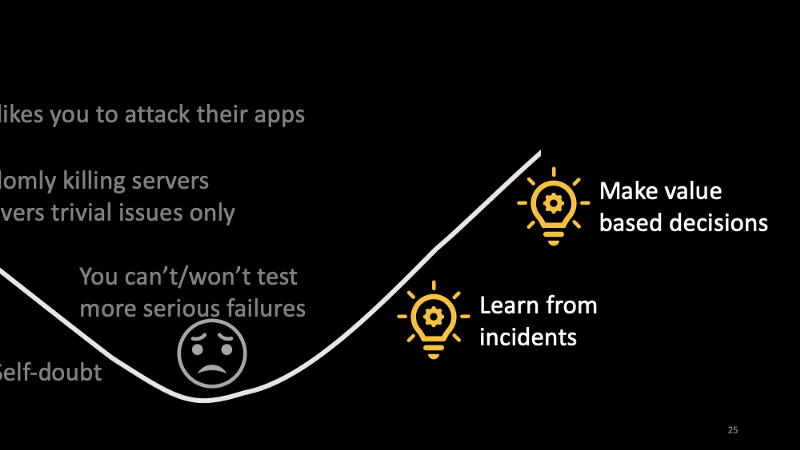
And then, learn to make value-based arguments and decisions.
Slide 26: How do you learn from incidents?

But how to learn from incidents? I don’t know. There is no documented text-book approach to learn from incidents. I took a particular approach to learn from incidents, which allowed me to make some observations and form new opinions. I’m sure there are other styles to make different observations.
That is why learning from incidents needs to be part of your org culture. You want everyone, and not just a few, learn from incidents.
Slide 27: How does it feel when you learn from incidents

While there is no textbook approach to learn from incidents, we can describe how it feels when you begin to learn from incidents.
Slide 28: Learning from incidents

First, you’ve built and updated several mental models of how the system works when it does, and doesn’t when it doesn’t. You have a better understanding of the scale and complexity.
Second, you’re not chasing symptoms but are beginning to understand the system as a whole. For instance, instead of creating a backlog of action items after each incident, you may start to look for systemic improvements.
Slide 29: Learning from incidents (Continued)

Third, you begin to understand the role of people, processes, and tools for success as well as failure. You will realize that resilience is not just about code, config, and servers, but it is also about the culture.
Last, you’re able to articulate the value of hygiene investments, including chaos engineering.
Slide 30: Lessons Learned

Lessons learned.
Slide 31: Learn from incidents

Lesson number one — learn from incidents. The need for and value of chaos engineering will fall in to place once you take the time to learn from incidents.
Lesson number two — sorry, but there is no lesson number 2.
Slide 32: Thank you

Repeating what worked for others may not get you far. Increase the time you spend on the “as it is” state to discover what works best for you.