
Taming the Rate of Change
Monday, November 19, 2018
These are great times for pushing code to production. Thanks to the cloud, micro-services, and investments in CI/CD pipelines, teams that used to release code once or twice a month to production until a few years ago are now introducing production changes several times a day.
For example, at the Expedia Group, which is where I work, we are witnessing a significant increase in change frequency (number of production changes a day), with change lead time (from committing code to a successful production deployment) for most changes in minutes. See the chart below that shows change frequency over the last two years.
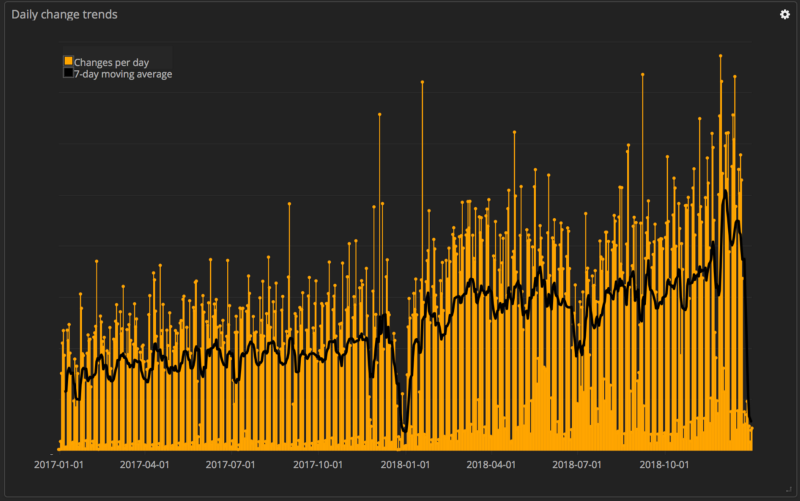
Change frequency is an indicator of time to create business value. In order to create value in a given amount of time, you need to be able to release your code a certain number of times and learn from those changes. The less frequently you release, the longer it can take to create value. Increase in rate of change shows that you’re reducing the time to create value, thus increasing team performance. Conversely, low change frequency indicates high time to create value and low team performance.
As the 2018 State of DevOps report says,
Those that develop and deliver quickly are better able to experiment with ways to increase customer adoption and satisfaction, pivot when necessary, and keep up with compliance and regulatory demands.
However, change frequency alone is not a sufficient measure of team performance. As the same State of DevOps report aptly captures, production stability is an equally important measure of team performance. What good is high change frequency if the production environment is falling apart often for long periods of time? There is also empirical evidence to show that incident frequency stays low when change frequency is low. See below to notice a correlation between incident frequency (red line) and change frequency (green line) when the change frequency low. The correlation is seen during periods of holidays when fewer changes were being made in production.
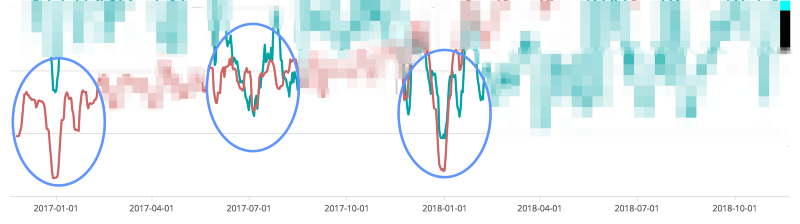
Update: See my later article Incidents — Trends from the Trenches for more evidence. My analysis of several hundred production incidents shows that change is the top trigger behind incidents.
But can an organization sustain increasingly high change frequency while simultaneously improving production stability? Don’t the tools and cultural changes used to increase change frequency also improve production stability? It depends. The very tools and cultural changes to increase deployment frequency may also contribute to increased fragility.
Based on metrics for deployments (first two rows in the table below) and stability (third and fourth rows), the DevOps Report also categories teams into the elite, high, medium, and low performance. Once you start investing in micro-services and CI/CD, teams move from low/medium performance to high/elite performance based on deployment metrics.
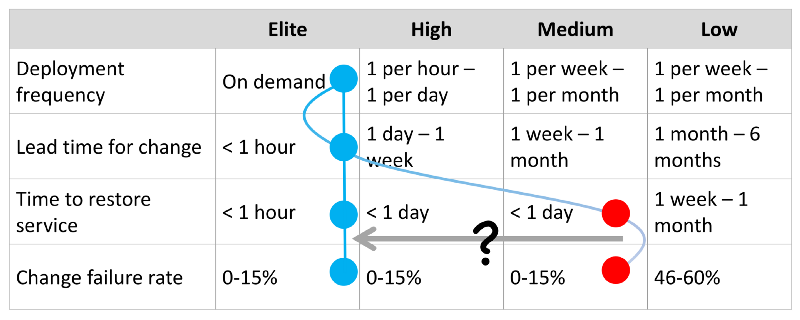
However, a similar transition based on stability metrics is not automatic. Why so?
This question has no simple answer. Chaos people offer that continual chaos testing will help surface fragility. Monitoring and observability people want you to integrate with their tools to see what is going on. Service mesh people ask you to adapt their solutions to baking some of the stability best practices into your application runtime. The answer is a mixture of all these and more.
In this post, let me explore what is likely happening today, and what it might take to improve stability without sacrificing speed.
Observation: Physics of Interconnectedness
Interconnectedness is a common attribute of most contemporary architectures. Our systems are an interconnected heterogeneous set of fast-changing and slow changing components.
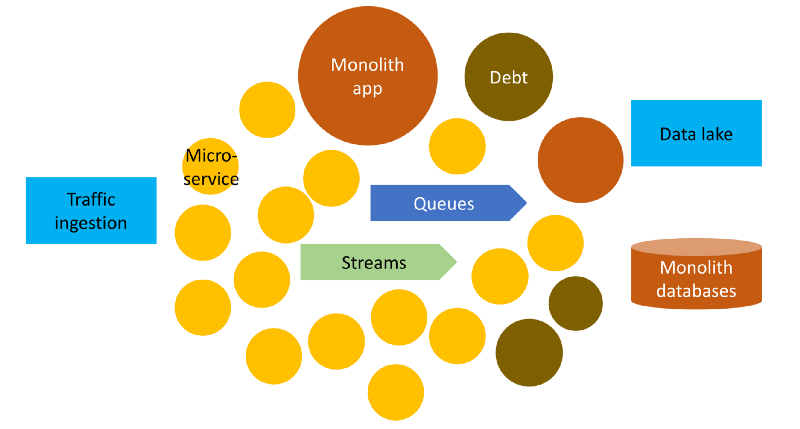
From experience, we can make the following observations of such architectures:
- Since not every part of the architecture has the same need for high change frequency, each part may get different levels of people and time investments. You may chip away some parts of a monolith to gain change efficiency for those parts, and leave the remaining untouched. Consequently, monoliths and debt remain integral to some of our systems for far longer than we expect.
- As it is getting easier to introduce new apps, overall architectures of our systems are changing faster than we can document them. This puts time pressure on the available knowledge and fragments team memory.
- It has never been easier to introduce a diverse set of languages and frameworks into the architecture, leading to another dimension of heterogeneity.
- With new code comes newly hidden assumptions about how various parts of the system work in the happy path, let alone assumptions about boundary conditions and failure modes. Every person making local decisions makes those with a peripheral understanding of how other components work. This is unavoidable as we can’t fully grok the complexity of our systems.
- Cost and complexity of replicating these architectures end to end in dev/test environments are rapidly increasing, which is leading to testing a subset of changes directly in production. Testing in production is an acceptable and needed practice now.
- Though a number of tests still get run in dev/test environments, most of those tests are localized and don’t exercise the interconnectedness of our architectures. The same is true about stress testing.
- Traditional capacity/stress testing assumes that our systems are linear, producing predictable and proportional outputs given valid inputs. However, interconnectedness makes the relation between inputs and outputs of the overall architecture non-linear. The components of the architecture may appear linear, but not the overall system. Past success, based on certain initial conditions and inputs, therefore, does not predict future success.
- Consequently, we don’t get to fully experience the dynamic and non-linear nature of our architectures until when there is a fault in production.
Whenever I participate in incident response, I take interest in observing how the participants reason about what went wrong and how to recover. Discussions on the bridge and incident Slack channels demonstrate some of the above observations. Participants offer assertions about what went wrong, and what should be done to fix. They base it on their own certain, deterministic and causal understanding of how the system is supposed to behave. Some would be right and some would be futile guesses. Sometimes resolutions are quick, and in some cases, resolutions take hours.
Observation: Unclear or Porous Fault Domain Boundaries
With rapid change, new components come into critical paths often. What was a stable path yesterday may have a few new components today with not-yet-well-understood failure modes. This leads to unclear or porous fault domain boundaries.
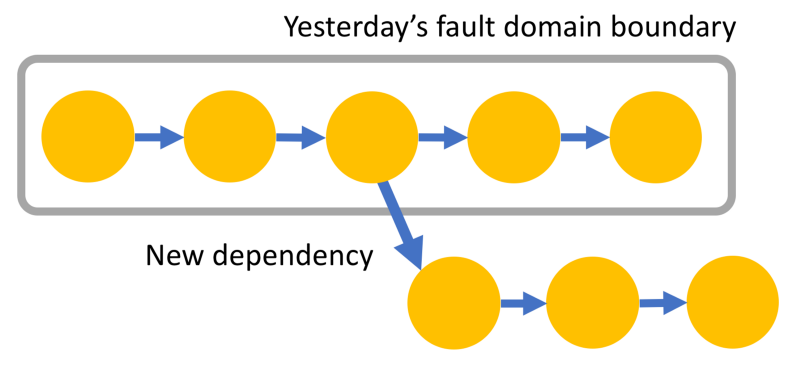
You may have had confidence till yesterday that a failure inside the fault domain does not cascade outside, and vice versa. New dependencies can erode your confidence quickly. Was the timeout for the new dependency configured correctly? Was that new dependency aware of the new traffic you may be planning to take? Is that dependency soft (i.e, we can still the request albeit in a degraded mode? Or hard (i.e., a fault in that dependency cascades)? You may not have enough time to catch up to answer such questions as the architecture is constantly changing due to high change frequency.
Observation: Incomplete Automation
Automate everything is a great slogan. In reality, automation is rarely complete.

There are several reasons why.
First, most frequently executed parts of our workflows get the highest priority for automation investments. For instance, CI/CD investments for stateless apps and services far outweigh similar investments for stateful parts. Stateful parts include your self-hosted databases, caches, queues, streams etc. The rationale is simple. In any given architecture, the need for change frequency is usually higher for stateless components than for stateful components. The usual attitude is to let the in-house expert deal with the stateful parts. “How was that database setup?” — you ask. The answer may be, “We don’t know. The DBA (or name your expert) set it up for us.”
Similarly, if one of your clusters is known to fail 3–4 times a year, would you spend two sprints to fully automate it, or jump into those failures to fix whenever there is a failure? Though the latter is nothing but unplanned work and contributes to the accumulation of forgotten failure modes, Managers and prioritization decision makers often pick the latter over the former. This seems counter-intuitive, but most people don’t work across long time horizons when prioritizing work.
Second, you need closed-loop automation for lights out management of systems. In a closed loop system, an observer monitors common failure conditions and autonomously takes corrective actions. However, building closed-loop automation is hard and time-consuming. Thanks to modern frameworks like Kubernetes, we’re in a much better spot today than ever before to implement closed-loop automation. However, having a solution is different from actually using it. This could be because you invested in your current automation sometime before a solution came along, and you may have sunk enough time, resources and processes to quickly change it all.
Third, the ease of use of cloud services makes it very tempting to create and configure resources manually through cloud consoles and CLIs. We all know it is wrong but do it anyway. As memory fades and team composition changes, those become brittle to change.
Configuration drift is one of the painful consequences of incompleteness of automation. Drift is like tree rot. It happens slowly, one config variable at a time, one hidden assumption now and then, just a few misconfigured alerts, and one more manual tweak here and there. That’s how drift accumulates over time.
Over my career dealing with infrastructure and automation, I’ve witnessed many cases with drift accumulating over a period of time to disrupt planned work, degrade critical services, cause difficult to explain bugs, or long times to restore because a critical team member is not on the bridge and so on. The lesson I learned is to always strive to increase the level of automation but also expect drift. I would plan to measure and monitor for drift regularly, and not blame incompleteness of automation for the failures drift may have caused.
Observation: Chaos Without Safety
Chaos engineering is not about randomly introducing faults into production systems. As Principles of Chaos Engineering explains, The idea of chaos engineering is to come up with hypotheses, create conditions to test those hypotheses, and then prove or disprove. Through such hypotheses testing, you gain a better understanding of the physics of your system. You help surface hidden and forgotten assumptions. Such understanding is essential to time to restore when failures happen.
However, despite some industry success stories, and even though chaos engineering is nearly 9 years old, its practice is still nascent in the industry. It is not often you would run into a team that says “We understand the value of chaos engineering. So we allocated x% of the development budget for chaos engineering practices”. A more likely answer is “This just isn’t the time to deal with chaos when we’re overbooked and understaffed. We’ll look at it later.”
As a mainstream activity, chaos engineering is perhaps where automation was 5–8 years ago, and experimentation (such as A/B testing) was 10+ years ago. So, what gives?
I see a few reasons for this hesitation.
(In this discussion, I’m ignoring those that that like to treat production systems as sacred that must not be willfully broken. Can’t help you. Sorry.)
First, a lack of confidence of recoverability from intentional failures inhibits the practice of chaos engineering. Would the system survive? What if we end up creating a massive production outage? Do we have the time to deal with the aftermath? Even in organizations that don’t punish people for breaking production systems on purpose, lack of confidence is a blocker for chaos testing.
Second, chaos engineering, when practiced in poorly understood complex environments, can tip the system beyond the point of equilibrium. You may not have the safeguards necessary to contain the effects of a chaos test. An intentional failure can quickly cascade, and lead the system into the zone of instability.
Finally, most enterprises lack dependable disaster recovery environments and practices. The fault domain, in such cases, envelopes the entire production environment across one or more data centers. Consequently, when a chaos engineering test goes berserk, there is no escape pod to fail-over to a healthy environment. Your only option is firefight the failure in place. Who would want to intentionally create a large fire, and then jump to fight it?
Culture of Safety to the Rescue
Stability concerns amidst high change frequency is a new reality for us to accept and adapt to. Like most things, stability consideration is not the sole terrain of any single tool or a practice.
Below are three phases of practices to consider to develop a culture of safety.
Before the change/Normal course
Design and build for redundancy: Redundancy helps improve safety. Lack of redundancy impedes your ability to test failure hypotheses, and thus your understanding of the physics of the system.
Pipelines to release safely through progressive or compartmentalized delivery, feature flags, blue-green deployments, canary releases, and finally change logging.
Pipelines to rollback: Sometimes rolling back suspected change may be the quickest option to restore from failure. Exercise CI/CD pipelines for rollback.
Failover testing: This is an important activity to perform to increase confidence in chaos engineering, and to practice reducing time to restore by way of traffic shifting. This type of chaos testing can be much more valuable than simply turning off random machines in your environment.
During an incident
Change visibility: Quickly review changes to isolate potential suspects.
Rollback: Rollback suspected changes.
Roll forward: If rollback is not possible, rolling a new forward may be your next best option, provided you’ve visibility into key production metrics.
Failover: If you can’t rollback, or can’t push a new fix, then fail-over to a healthy copy. This step takes practice. The investments made during the normal course to failover traffic to a redundant copy will come in handy here.
After the incident
Postmortem: The amount of time you spend after the incident is more important than the time spent during the incident.
Low/medium performing teams don’t spend enough time after an incident to analyze what happened, to curate and document the findings, lessons learned, and action items; and to follow through those action items in a timely manner. They get burnt out during the incident, and attention drifts away to other things in a few days.
On the other hand, high-performance teams conduct periodic operational reviews to review postmortems and follow up actions. They don’t let go of the post-incident learning phase.
Consider each postmortem as an opportunity to learn and reason about the physics of your systems, and not just as a chore to report the findings.
Post-incident validation testing: Once the fixes are made, validate design and code changes by testing if the system would survive a similar failure. Most available chaos testing tools help mimic a variety of failures. Test it in production as much as possible to increase confidence.
Remember that safety does not mean slowing down. It does not mean batching a large set of changes into big bang releases. A culture of safety means being deliberate of the actions, aware of the production environment, and conscious of customer experience. It requires you to develop an understanding of the complexity and the interconnectedness. The more you understand, the faster you can go.