
Cloud Optimization Circus
Wednesday, June 20, 2018
If you are a cloud adopter rapidly adopting cloud services, but not developing the finance governance muscle, you will certainly be visiting the cloud optimization circus frequently.
I compare cloud optimization exercises to going to a circus because those exercises invite all the same characters and emotions that you find in a circus. There is fear (of wasting money), trickery (by folks showing you how much you could be saving), illusion (of savings that don’t exist where you’re told they exist), excitement (of finding savings), and drama (of playing heroics). It may be fun and entertaining once or twice. Not so when you’ve a mission to accomplish, unless, of course, the mission is going to the circus.

Security and costs are the two biggest risks of cloud adoption. Security is a risk because, teams that optimize for agility on cloud tend to ignore security initially only to realize later. Cloud certainly gives the building blocks for security, but it is up to you to use the building blocks in the intended manner. Cost is the second on my list. Cloud is cheaper once you understand how cloud costs work, and develop the governance muscle. Cloud can be very expensive otherwise.
Spend vs Demand
Back in February 2018, I gave a talk at the Container World Conference on Are We Ready for Serverless. One of the key themes of my talk was that serverless frameworks like AWS Lambda are the closest available today to ensure required supply of resources follow the demand for resources. Here is a hypothetical supply-demand chart.
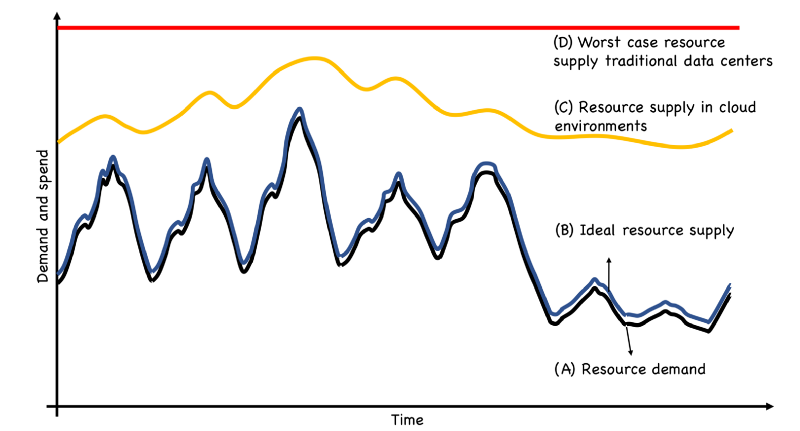
Curve A shows the resource demand. This is the sum total of all resources required to run the business, which in this example varies during the day and the week. Curve B is the ideal supply and spend. In the best case, supply, and hence spend, closely follows the demand. This is possible with serverless frameworks. Curve C is what usually happens in cloud environments. Though supply varies due to auto-scaling and ephemeral usage, such as dev/test activities during the day tapering off over nights and weekends, it usually stays above the resource demand. Curve D shows the supply in data centers where it typically stays flat.
Let’s ignore serverless here. Though it is the most efficient and requires no effort to maintain the spend to tightly follow the demand, only a tiny fraction of total cloud workloads today run on serverless frameworks like Lambda. Serverless potential is yet to be realized at large, and each enterprise will have to carve out its own journey in the coming years.
Majority of cloud workloads today run on virtual machines followed by multi-tenant managed services including network and storage services. Though some managed services bill you for what you need and use, for the vast majority, the task of making the supply (C) to efficiently follow the demand (A) falls on development teams, an assortment of nascent tools, and mostly reactive practices.
However, the task of making the spend efficiently follow the demand is easier said than done. Cost consideration is usually an after thought as most cloud adopters’ early focus remains on speed of delivery and not cost efficiency.
Unfortunately, this topic does not get much attention in the cloud community. Cost worries are usually brushed aside with suggestions like “use auto-scaling”, “use spot instances”, “fix your automation to clean up”, or “turn off your machines when you leave work”. Look at conference talks, meetups and blogs — you will rarely hear about spend management practices, how to project costs, how to understand detailed billing data, how to maintain efficiency, best practices, failures, lessons learned etc. Consequently, most cloud adopters fail to realize the strongest lever that cloud offers — which is to manage the spend to vary with the demand. But such a lever won’t exercise by itself. You need to equip the organization with tools, practices and processes to actually do the work.
For enterprises migrating from traditional data centers to the cloud, spend management is a lever that they don’t have in the data center. In the data center world, you do your best to estimate what you need in a year or so from now, spend all that, and hope it meets the need. There is no turning back if you find yourself with spare capacity. This is why most tech teams operating in traditional data center environments consider data center resources as free for all practical purposes. It would be a great missed opportunity to not deliberately practice efficient spend management as you ramp up on the cloud.
Over the last two+ years of leading cloud migration at work, I’ve had a chance to look at this area very closely, and take part in building a successful cloud finance governance engine to increase cloud spend efficiency. Let me share my observations and experience.
Problem 1: Data is Plenty, and Insights are Shallow
A RightScale post from November 2017 states that about $10 billion is wasted each year across AWS, Azure and Google. Another report by BusinessInsider from Dec 2017 proclaims that “companies waste $62 billion on the cloud by paying for capacity they don’t need”.
These are staggering numbers for sure. In my experience, we can’t quickly project such numbers at the enterprise level without producing a bottom up baseline through exercises like zero-based budgeting applied to every workload. These are time consuming activities involving testing every workload for the best price-performance ratio. Even predictions produced by tools like AWS Trusted Advisor and cloud cost dashboarding tools like CloudHealth fall short in reality as these tools lack the context of the workload. Consequently, most dev teams don’t often pay enough attention to these predictions.
Furthermore, detailed billing reports like the AWS Cost and Usage Report provide a wealth of detailed billing records. Here a few sample billing records.
73xfp4egijc5zblnu4easfnmvmnw4gsdxpwo7v2jxu4epqct6q7a,2018-06-02T01:00:00Z/2018-06-02T02:00:00Z,,AWS,Anniversary,xxx,2018-06-01T00:00:00Z,2018-07-01T00:00:00Z,xxx,Usage,2018-06-02T01:00:00Z,2018-06-02T02:00:00Z,AmazonS3,USW2-Requests-Tier2,ReadLocation,,cf-templates-xxx-us-west-2,1.000000 0000,,,USD,0.0000004000,0.0000004000,0.0000004000,0.0000004000,"$xxx per 10,000 GET and all other requests",,“Amazon Web Services, Inc.",Amazon Simple Storage Service,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,S3-API-Tier2,GET and all other requests,,,,,,,,,,US West (Oregon),AWS Region,,,,,,,,,,,,,,,,,,,,,,,,,,, API Request,,,,us-west-2,,,,,,AmazonS3,Amazon Simple Storage Service,xxx,,,,,,,,,,,,,,,,USW2-Requests-Tier2,,,,,,,,,xxx,xxx,OnDemand,Requests,,,,,,,,,,,,,,,,,,,,xxx,,,,,,,,,,,xxx,,xxx,xxx,,,xxx,,,,
ip4a5gnjucytps5c7nittxxgwj3jo5yc5sszhu4kkk2wqqyzv4rq,2018-06-05T19:00:00Z/2018-06-05T20:00:00Z,,AWS,Anniversary,xxx,2018-06-01T00:00:00Z,2018-07-01T00:00:00Z,308506315341,Usage,2018-06-05T19:00:00Z,2018-06-05T20:00:00Z,AmazonVPC,USW2-DataTransfer-Regional-Bytes,VpcEndpoint,,arn:aws:ec2:us-west-2:xxx:vpc-endpoint/vpce-xxx,190.5361101758,,,USD,0.0100000000,1.9053611018,0.0100000000,1.9053611018,$0.010 per GB - regional data transfer - in/out/between EC2 AZs or using elastic IPs or ELB,,“Amazon Web Services, Inc.",Amazon Virtual Private Cloud,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,US West (Oregon),AWS Region,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,Data Transfer,,,,us-west-2,,,,,,AWSDataTransfer,AWS Data Transfer,xxx,,,,,,,,,,,US West (Oregon),AWS Region,,IntraRegion,,USW2-DataTransfer-Regional-Bytes,,,,,,,,,xxx,xxx,OnDemand,GB,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,,
Depending on your scale and activity, you might see millions of records like these every day. These records span over tens of resource types and product families, and tens of thousands of usage types. As new features are introduced, and as your adoption grows, the volume and detail, and hence the complexity of these records, also grows.
On one hand, having such a wealth of data shows the true power and potential of on-demand pay-per-use model of the cloud. This data can help you understand the implications of your architecture choices, be able to correlate workload patterns with costs, and make price-performance trade-offs. Insights from this data, when gained, can help bring cost awareness to the engineering culture.
On the other hand, most billing tools available today mainly focus on providing dashboards with high level metrics, but not many insights. For example, in one particular case, recommendations from Trusted Advisor showed significant potential savings in certain areas, while analysis of the raw billing data revealed much bigger opportunities elsewhere. The latter required deeper understanding of the billing data to spot inefficiencies.
Developing a deep and solid understanding of billing records is an engineering problem that consumes time and investments. It’s like understanding operating system level metrics. It is not optional to not understand such metrics. You’ve to build tools to process the data, visualize, and then derive insights. You can not also centralize all this to one particular tech team or a finance team, as you need every team spending on the cloud learn to gain their own insights. Such insights need to complement performance metrics to gain awareness of price for performance. This is why I believe that cost awareness must be part of the engineering culture, and it starts with developing an understanding of billing data.
Problem 2: Optimization Practices are Reactive
Unlike other drivers like dev agility, availability, and security; cost related practices often tend to be reactionary. Cost concerns come to the front seat only when there is a sense of urgency to reduce cloud costs. Otherwise, cost concerns get left in the garage back home. Whenever there is a realization of cost increases beyond budgets, organizations scramble to conduct optimization exercises, and when the dust settles, go back to the business as usual.
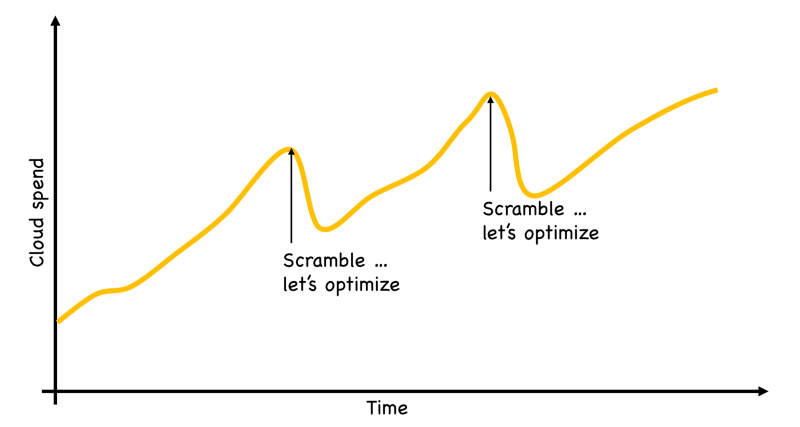
Part of this is due to Problem 1 above, which is not looking at the billing data, and/or not gaining enough insights from the data, and thus not being able to incorporate cost awareness into the engineering culture. The remaining of it is due to the holy trinity of cost, speed, and quality.
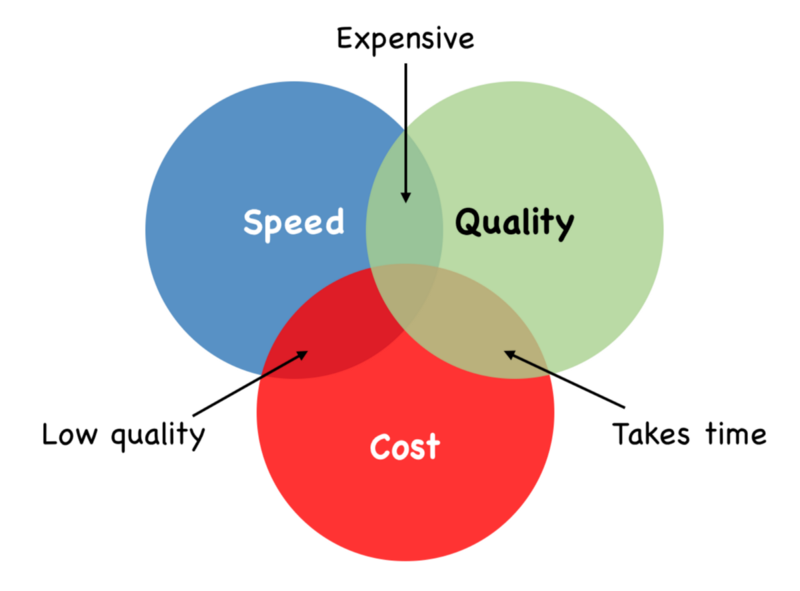
In order to produce an outcome of a certain quality, at any given time, you can either move fast while spending more, or move slow and be efficient. You can’t maximize all the three at the same time. The key question to ask therefore is, how much cost inefficiency are you willing to tolerate for a given amount of quality and speed.
Problem 3: Stigma and FUD
Though we hear about wastage on the cloud from reports like those I cited above, apart from a few “how we saved such and such by doing so and so” blog posts, we don’t hear much about building sustainable practices of spend management and governance; and most importantly real stories about failures.
There is a reason why. Most of us mentally equate having to optimize cloud spend to the business not being healthy. We compare it to other usual cost cutting measures that most companies take at various points in their cycles, such as letting people go, avoiding business travel, reducing discretionary spending etc, shutting down offices etc. Though more experienced managers and leaders see these as natural acts of cost governance, common perception remains otherwise. A shadow of stigma follows cost optimization.
However, most successful companies build cost governance into everything they do, whether it is hiring, business travel, discretionary spending, or technology related spending. Cloud costs are no different. Acknowledging that cloud spend is a variable that you can manage, that you must maintain the spend at a certain efficiency, and removing the stigma from cost optimization are essential to building a culture of cloud cost awareness.
Wherever there is a stigma, there is FUD. I’ve heard stories of cost optimization practitioners in the wild that make claims like “we will show you how to save $XXX, just give us $Y”. One friend once shared a story of a consulting team proposing to optimize for a percentage cut of the savings realized. Do you remember “termination assistance” from Up in the Air (pun intended)?

Such approaches might make sense in places where cloud adoption is not strategic, and is treated as a utility, like a third party maintaining your corporate media web site. However, these approaches don’t produce sustainable results for anyone running serious workloads on the cloud. While not rejecting the need to seek help, you’ve to equip yourself with tools, automation and cultural changes. This is the philosophy behind DevOps — you make teams autonomous and hence accountable for development and operations for higher team performance. The same goes for cloud costs too.
Cloud Finance Governance and Ops
This brings me to commonly dreaded term “governance”. Instead of treating cost optimization as a necessary evil, what we need is a practice of cloud finance governance and operations. Optimization is a part and parcel of governance. Here is how I describe cloud finance governance.
Cloud finance governance is pushing for responsible spending practices, and introducing checks and balances. It is about learning to operate spend management levers to trade between between speed, cost efficiency, and sometimes even quality.
Governance is not a bad word. Governance is not bureaucracy. Governance is not introducing roadblocks. When done right, governance is empowering, rewarding, and helps us exercise new muscles. Governance is what responsible families, cultures, societies and businesses must do in order to be adaptable and be resilient.
While prescribing a general purpose blueprint for how to practice cloud finance governance is tricky as each organization needs to determine what works best for them, below are some of the essential building blocks.
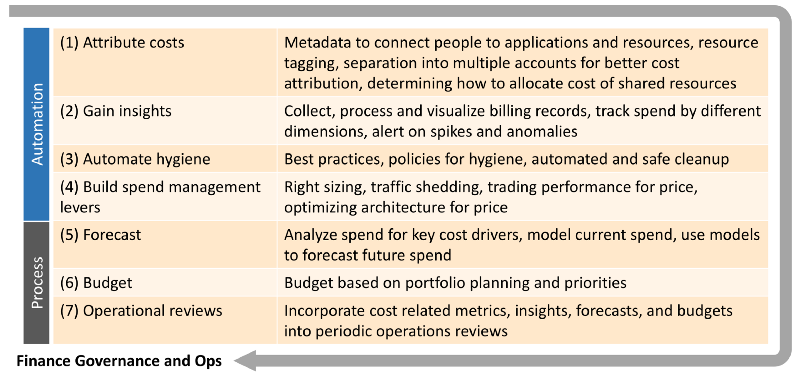
1. Attribute Costs
You can’t govern and optimize what you can’t measure. I was in situations with charts showing large unallocated cloud spend on a big screen in front, and struggling to explain where that money was going. You can’t optimize, let alone govern, if you don’t know who is spending what. Resource attribution to people and teams is fundamental to operating successfully on the cloud for cost as well security reasons.
There are several techniques to consider to maintain high percentage of attributed costs:
- Metadata to map people and the organization structure to applications and resources
- Resource tagging of all taggable resources — be aware that not all cloud resources are taggable
- Using separate accounts for different types of workloads to reduce accumulation of shared expenses — particularly those due to untagged/untaggable resources, including network ingress/egress costs, NAT gateways, firewalls etc.
- Modeling how to attribute cost of shared services — your organization may be running large shared services for logging, monitoring, caching, proxying, analytics, experimentation etc. Since these are used by many teams, you may end up in a situation of nobody being able to explain the cost of such services.
2. Gain Insights
The next step is to gain insights from the billing data. Insights aren’t easy and automatic. I approach this step by first observing cost and usage data across different dimensions (time, regions, accounts, dev/test/production environments, resource types, usage types, instance types, allocated vs unallocated costs, etc), asking questions, making hypothesis, and validating those hypothesis. This is an iterative process over time.
In order to do these, you need access to the raw billing data, stored and indexed in a form that allows fast and easy queries. At work, we built a data warehouse using Redshift and ElasticSearch for billing data. This system loads raw billing data as soon as it lands in S3, merges it with the metadata of people and applications, and loads into an ElasticSearch cluster for queries and visualizations. This process helped us several times to improve our overall understanding of costs, efficiencies and inefficiencies, and areas of improvement.
3. Automate Hygiene
While we like to automate everything, in reality, automation is never complete, and the degree of completeness varies by what you’re optimizing your automation for.
You may, for example, optimize for speed and availability, and decide to leave older deployments for a week or to allow for rollbacks. You may optimize for performance for your analytics workloads and decide to keep all your offline data in the S3 standard access class, and run the compute on pricey instance types. You may have a bug in your automation that forgets to propagate tags from EC2 to EBS, thus increasing unattributed costs. Your teams may have forgotten to upgrade some legacy EC2 instances that may be pricier for the same performance. I’ve seen all such scenarios and more that lead to waste.
You can improve hygiene by crafting policies (such as “all unattached EBS volumes shall be deleted after 48 hours”), and then automating those policies.
4. Build spend management levers
Remember that cloud spend is not a fixed sunk cost. It is a variable expense that can you manage. There are several levers possible:
- Continually iterating the architecture to improve the price-performance ratio. Though it is commonly referred to as right-sizing, in reality, it is all about testing, looking at past data, and adjusting resource choices to improve price-performance ratio.
- Shedding unnecessary/unwanted traffic
- Scaling down passive regions (for applications using active-passive architectures)
- Adjusting SLAs for your analytics jobs to take longer time to complete
- Using cheaper tier options for S3 and EBS to trade performance for cost efficiency
- Adjusting data retention policies
- Using cheaper resources for test workloads
Furthermore, if you’re still running in the hybrid mode with some apps serving traffic both in your data centers and the cloud, another lever may be to shift traffic one way or the other to balance between variable cloud costs and fixed data center costs.
5. Forecast
Forecasting is another important aspect of developing a finance governance process, particularly for those moving workloads from the data center to the cloud, or those building new systems. During such phases, cloud spend tends to increase at a higher rate than in the steady state. Forecasting is less reliable during such phases as you may not have past data to build forecasting models. Regardless, you can correct for this by forecasting more frequently — ramp up some volume of traffic, build models for forecasting, forecast, then ramp up more. Also read Cloud and Finance — Lessons learned from a year ago on this topic.
6. Budget
Forecasting is what you expect to spend in future based on your cloud adoption plans, your team velocity, and the architectures your team is building. The budget tells you how much is being set aside for that area of spend. The difference should tell you how to tweak the plans, architecture, and levers you can exercise to meet the budgetary goal. Usually finance teams determine your budget.
7. Operational Reviews
Lastly, incorporate all cost related metrics, and insights into your periodic operational reviews. Most teams use such rituals to review overall KPIs of applications, and the status of projects the teams are working. Add cost related topics to the same. This is a place to observe billing data, to ask questions to develop better understanding of the data, to identify ambiguous areas, and to keep on improving the governance muscle.
To reiterate, cloud gives you many levers to manage costs. Discovering and exercising those levers requires thinking of how to govern cloud costs, and building the automation and processes to develop insights into costs, creating spend management levers, and knowing how to make cost vs speed vs quality tradeoffs.