
State of AWS Compute Pricing
Saturday, February 25, 2017
As flexible as it is, compute in AWS is optimized for the old capex world. It is a world where demands are predictable, consumption can be planned upfront, and things don’t change often. A culture of centralization for forecasting and budgeting, and approvals to determine who can use what and for how long, helps remain optimal in this world. In other words, you have to think and act like an efficient enterprise data center operator, and not as a cloud user to get the most bang for the buck. On the other hand, if you have bought into elasticity, on-demand consumption patterns, seasonal highs and lows, a culture of choice, and incremental test-and-learn development, you have to brace yourself for some complexity.

Instance Reservation is an Anti-Pattern
I’m not the first one to say this. Reserving compute instance hours for a year or three years with or without capacity guarantees for a given instance family and type is just like buying servers in data centers. It is a cloud anti-pattern, as it requires you plan your capacity needs upfront. You need to think in terms capex and not opex to use instance reservations efficiently.
Below is an example of what happens when you try to use instance reservations with an opex mindset (aka the cloud mindset).
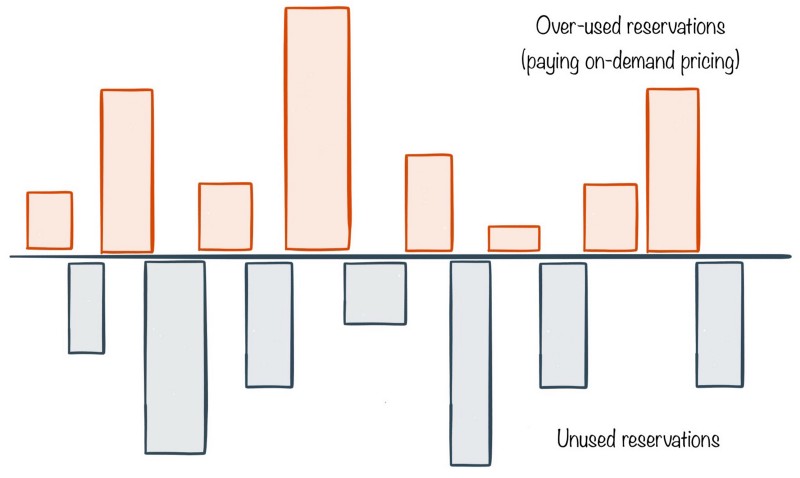
Each bar in the above diagram represents number of instance hours for a given instance family/type in a given region. The number of bars grows as you consume more instance types in various regions.
Imagine you purchase reserved instances for certain types on a given day. A month later you look at the invoice and notice two patterns.
- For some instance types in certain regions, you’ve run out of reservations and are paying on-demand prices for additional instance hours. These are the bars above the line.
- For other instance types in certain regions, you’ve not used the all the reserved hours for that month. These are under-utilized reservations shown with bars below the line.
Both the types of these bars represent inefficiency. Above the line, you’re paying on-demand prices. Below the line, you’re leaving money on the table.
The only way to reduce the sizes of these bars is by upfront planning. However, in a dynamic and elastic world, as teams figure out the right computing needs, these bars will always go up and down, and it takes continual tweaking to minimize the spread. The following are the options.
- Monitor reservations on a monthly basis, and purchase new reservations to avoid on-demand pricing. This helps lower the lines above the bar.
- Create an internal spot market as once shared by Netflix to increase utilization of unused reservations.
- Sell unused reservations in the spot market. However, as Jan Wiersma shows, the spot market to sell reservations is a ghost town.
All these options take engineering effort and involve some operational complexity. This is a result of forcing capex mindset into an opex centric cloud world.
Spot Instances are Poor Abstractions
An often suggested answer to reduce compute costs is spot instances (or Google’s preemptible virtual machines).
Spot instances shift the complexity of dynamic placement, task preemption, rescheduling, etc. from the cloud provider to the user. Spot instances work best when your workloads are idempotent, and you’ve a scheduler (like Mesos and Yarn) that can place workloads on instances, and move them around when instances go away due to changing demands in the spot market. Spot instances are not the best choice as general purpose compute.
It’s Time for Change
Capacity guarantees may be relevant for certain critical workloads for certain users. But reservations and spot Instances for cost savings don’t make sense. These are optimized for the seller and not the typical buyer. It’s time for these to die.