
Serverless: Looking Back to See Forward
Sunday, November 12, 2017
Last week, I attended an all-day CIO forum on cloud in Seattle, organized by one of Seattle’s top venture fund groups. Several notable speakers and panelists spoke about their views on containers and kubernetes, public and hybrid clouds, provider lock-in and portability amongst providers, and of course, serverless computing.
I observed two patterns that day. First, there is a genuine concern about cloud provider lock-in. Second, there is a desire and hope to avoid or at least minimize such lock-in by embracing open source abstractions and platforms, most notably Docker and Kubernetes. These patterns are best illustrated by the answer I got for my question to one of the key guests of the day.
My question was whether this individual would spend six months to build and launch a new service that works and takes advantage of everything one particular public cloud offers, or spend two years to make sure that the same would run on multiple public clouds. The answer I got was that, though he might start with the former for agility, he would invest in the latter for the long-term. The implication I sensed in this answer was that the latter is the right thing to do. I didn’t press on to ask if he had an opportunity to test this hypothesis in the real world.
While I’ve not shied away from stating my opinions on multi-cloud and cloud lock-in, this event made me acknowledge the necessity to take a few steps back from these views, and notice some changes that have been slowly happening over the last five plus years in the industry.
In this post, I would like to narrate three slow changing themes in the industry, and postulate where we might land in five plus years from now. My hypothesis for the future is that serverless services will take the center stage for most common application development, and consumption of open source for infrastructure automation and services will continue to drift from being strategic to opportunistic. Looking back to see forward might help us shape and take advantage of that future and not fight it to be left behind.
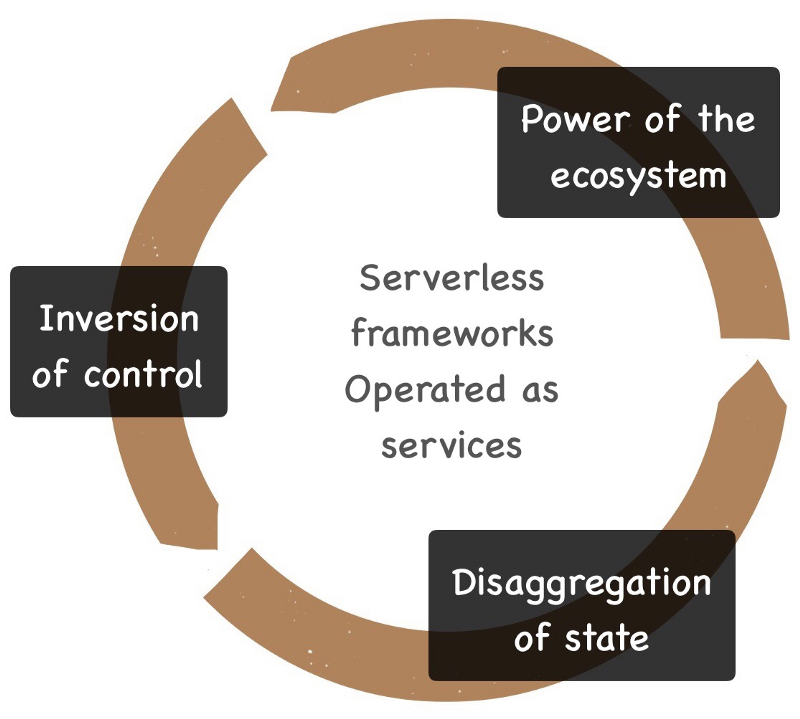
These themes are not independent, and are reinforcing and accelerating one another.
Theme 1: Inversion of Control
AWS Lambda is the first successful application of inversion of control for the data center. Inversion of control is a design principle in which applications receive flow of control from a generic framework. By implementing certain common and generic tasks, the framework relieves applications from having to implement those generic tasks at the expense of losing explicit flow of control.
Inversion of control is not a new concept. Wikipedia’s entry points to a 1998 reference. However, application of this concept at commodity scale to data center resources is relatively new. This is because of the complex nature of the common qualities that most applications need in the data center. These qualities include the following:
- Just-in-time allocation and de-allocation of resources like compute (baremetal or virtual machines), network segments (for network isolation), network filters (firewalls), load balancers, and storage (file or block)
- Elasticity of such resources to allocate nothing to as many as needed, with the needed quality of service
- Keeping applications robust and available in the face of common infrastructure failures
As essential as these qualities are, achieving these still takes Herculean efforts in most data centers around the world today. Just try to get a new 1,000 node Hadoop cluster in an enterprise data center. You would be lucky if you get a working cluster in six months. Though compute virtualization has helped to an extent, resources in data centers are still horridly non-malleable. Through a series of evolutionary changes, we are now getting ready to abstract this complexity into frameworks operated as services, and the early benefits from services like AWS Lambda are clear.
See below for the inversion of control moving custom purpose built automation into app frameworks operated as services.
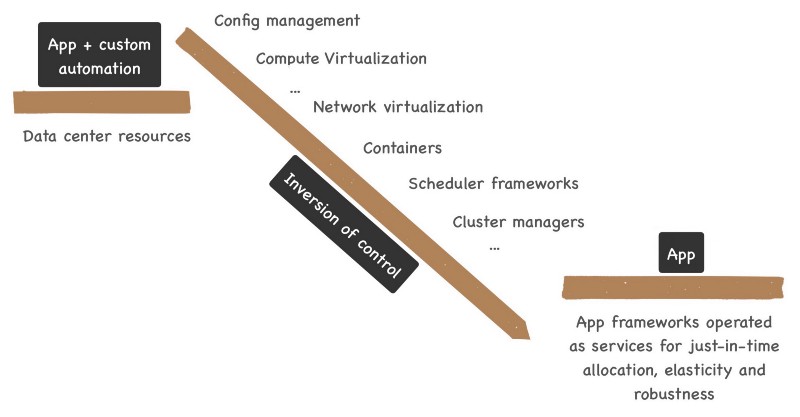
It is unfortunate that we call this inversion of control as “serverless”. Framework as a service is a less confusing choice to describe the new abstractions. Regardless, every development happened so far is helping us build better frameworks, and the trend shall continue.
Theme 2: Disaggregation of State
Most enterprises have built or used open source “platform as a service” tools that make it easy and quick to create, build, deploy and run applications. Such platforms succeed(ed) when dealing with stateless code like web apps or stateless micro services, but fail(ed) to tackle state. Examples of stateful applications include SQL or NoSQL databases, search clusters, key-value stores etc.
State introduces extra complexity into automation as it requires you to think of distribution aspects like cluster awareness, synchronization, consistency, sharding, replication, and partition tolerance; and quality of service aspects like fast startup, IO latency, IOPS etc.
Just think of how much code you could delete from Kubernetes if all it did was to run stateless microservices. Building generic automation abstractions for stateful systems is hard and time consuming, and most of all, it takes experience to get the abstractions right. Even replacing a failed node from a stateful system takes special considerations and most enterprises don’t dare automate such tasks for fear of losing critical data.

Moving state to external managed services like S3, Dynamo, BigTable, Spanner is lowering the bar for application automation, which is thus eliminating some of the complexity from frameworks operated as services for the provider. For the consumer, this trend is also eliminating operational tasks that system and database administrators usually perform.
Theme 3: Power of the Ecosystem
The most important change that is accelerating the adoption of serverless frameworks operated as services is the strengthening ecosystem of services in each public cloud today. Without the ecosystem, AWS Lambda would not have gained as much adoption as it did in such a short time.
Just to give an example, at Expedia, we ran over 6.2 billion invocations of AWS Lambda in October this year. Though this number is small when compared to other types of external or internal traffic we serve, Lambda’s rapid adoption would not have been possible without the surrounding service ecosystem with IAM, SNS, SQS, API Gateway, KMS, S3, Dynamo, Kinesis etc. Most of these Lambda functions are about 100–150 lines of long and are written in a day or two. Of course, we also built a deployment platform that makes creating and running Lambdas a breeze.
Without such a mature ecosystem, AWS Lambda would just be a curious cloud-enabled cgi-bin service.
To Fight or Not to Fight
These three themes are reinforcing and accelerating one another.
- Frameworks as services like Lambda wouldn’t be possible without disaggregation of state and a strong ecosystem of services.
- Similarly, adoption of S3 as an infinitely elastic data lake is fueled by the ease with which you can create and terminate data processing compute clusters like Hadoop map-reduce and Spark in a serverless manner without worrying about HDFS for state durability.
- Complexity shift from apps to the service ecosystem is clearing the way for faster development and adoption of frameworks as services.
Resisting any of these themes has a cost. For example, resisting AWS Lambda for fear of lock-in reduces agility, raises infrastructure cost, and increases complexity of automation. Not moving data from an enterprise storage system to a cloud storage service like S3 for fear of losing control on data increases cost of data storage, makes storage less secure, increases automation complexity, and increases friction for systems that need to deal with state. Not adopting cloud provider managed services for fear of lock-in reduces agility, and raises the cost, particularly the cost of lost opportunity.
What’s in store for the future then?
Cloud services will continue to shift the complexity away from applications further fueling adoption of frameworks as services on public clouds. Docker and Kubernetes will become less relevant in the developer land than they are today as proprietary frameworks take the center stage. This is not a threat to open source. Open source shall maintain its place in many other forms.
Despite fears, natural laws of economy will shift the gravity towards frameworks operated as services. Since these are services and not code, these will remain proprietary. AWS Lambda may have been the first of its kind but won’t be the last. There is a lot of code in the industry that needs to move to app frameworks operated as services, and we will likely see more frameworks in future.
Even when multiple cloud providers offer the same open source abstraction, portability will be unlikely due to proprietary warts and the proprietary service ecosystem.
In summary, here is my suggestion. Participate in this journey, learn and not be left behind.