
Fault Domains and the Vegas Rule
Friday, February 17, 2017
(Cross posted at https://techblog.expedia.com/2017/02/16/fault-domains-and-the-vegas-rule/)
Our teams at Expedia are active public cloud users. We use a simple design principle called the “Vegas Rule”, and a complimentary concept called “fault domain” to make resiliency-related decisions.
Fault Domain
A fault domain is a coarse-grained enclosure of apps, data and all the dependent infrastructure. The primary property of a fault domain is that any fault inside the fault domain does not cascade outside. All components inside the fault domain share the same fate. Below is an example. The outer circle represents a fault domain.
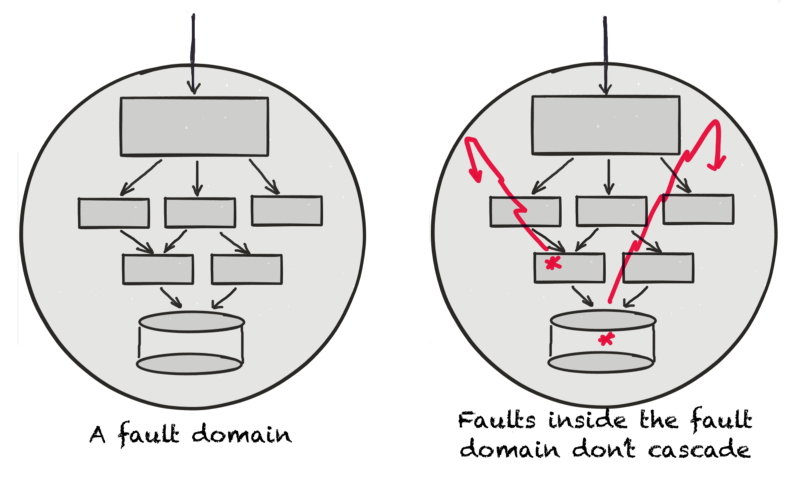
Any external dependency is soft, and the the services in the fault domain may, in the worst case, run in a degraded mode when that external dependency fails.
In order for a fault domain to be effective, a rule of thumb to apply is the Vegas Rule.
Vegas Rule
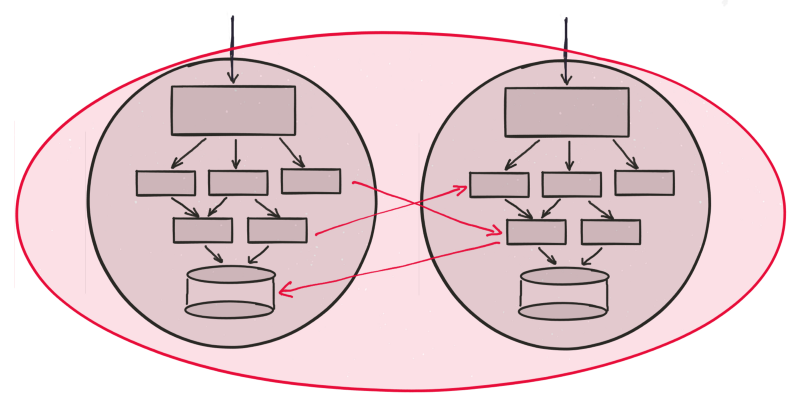
Our version of the Vegas rule states that “any request that enters a fault domain is fully served inside the fault domain”. When a fault domain does not honor this rule and the request goes through services outside the fault domain, those external services automatically become part of the fault domain thus extending its size. Potential exclusions for this rule include asynchronous communication (say, for database replication) between two fault domains or with an external service.
Below is an example. The red arrows violate the Vegas rule thus merging two fault domains into one large fault domain.
All About Time to Recovery
The real resiliency benefit of fault domains and the Vegas rule comes from having two or more fault domains. Vegas rule simplifies incident recovery procedures. Instead of identifying and fixing failing services, you can shift traffic away from a failing fault domain to other healthy fault domains.
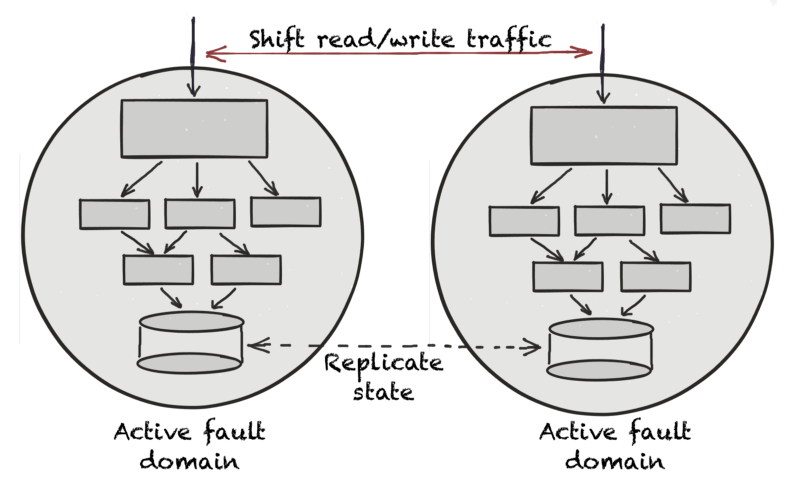
Vegas rule works for services that use active-passive databases too.
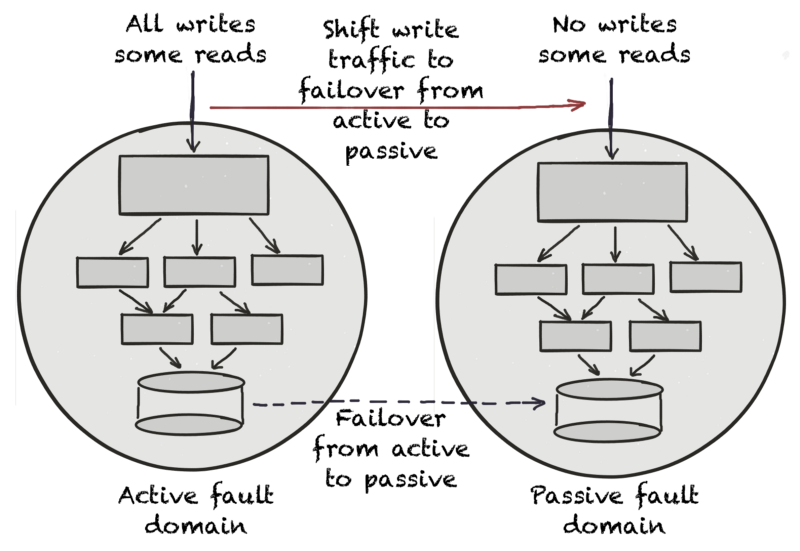
When you don’t consciously identify fault domains for apps, services and databases, or break the Vegas rule, traffic shifting may not help reduce MTTR. You may have to identify and fix failing services which increases time to recover.
I learned about this concept when working on provisioning and scheduling in an IaaS layer. You will find references to this concept in Azure and VMWare documents. The same concept works for applications and services too.