
Give Me Bare-Metal
Monday, November 10, 2014
“Give me bare-metal. I can put together what I need myself. I don’t need a cloud” — this is the gist of some comments I came across in recent months. One of the commenters just experienced Docker. Another managed to spin a cluster of front end apps in a few minutes using the Marathon framework on Mesos. I even heard a similar comment from a someone from the Yarn community; see Docker & Kubernetes on Apache Hadoop YARN for an example. However naive such a comment sounds like, I could not ignore the underlying sense of empowerment from using talk-of-the-day tech like Docker, Mesos, and Kubernetes.
While it is easy to take sides in debates about Docker, containers vs VMs, Mesos vs Kubernetes vs cloud platforms like OpenStack, take note that there are extremely important reasons why some of these are exciting to use. These are driving immense amounts of simplification for the user. What used to take large amount of code and operational procedures to implement commonly sought after ilities like availability, agility and efficiency is now getting simplified to some declarative assertions. Getting a VM is now considered boring. Dockerizing apps and deployments is new and exciting.

Underneath all this, some of the fundamental assumptions that the industry has made about Infrastructure as a Service, and Platform as a Service are getting disrupted.
Cloud platforms that offer nothing but VMs have been under threat for a while, but Docker has made that threat practicable. If I’m a front-end app developer, it’s much more convenient for me to use a container-based cluster management solution on bare-metal without dealing with VMs. After all why bother about provisioning and putting VMs together into a cluster when there is framework that does it for me, in addition to solving some of my app packaging needs?
Most private cloud programs, and even some smaller public clouds still start with compute as the primary offering. This is because compute is usually the first one impeding developer agility and it makes sense to solve it first. However, Docker is now making it easy to question the existence of compute-only clouds.
Platforms that require isolated and dedicated compute and storage clusters for each type of workload too are up for question. Such platforms aren’t able to run heterogeneous workloads on shared infrastructure to improve resource utilization. Though most CIOs love to talk about flexing down online workloads at off-peak hours to flex up batch workloads, the reality in most data centers is painted racks, i.e., dedicated servers/racks of compute and storage for different types of workloads. In these types of environments, cluster sizes are relatively fixed, utilization remains low, and moving capacity across environments usually requires manual changes. Scheduler frameworks like Mesos are set to solve resource sharing across heterogeneous workload types thus eliminating the need for separate environments. Note that true sharing still requires compute and storage with predictable performance characteristics with little or no interference, and a multi-tenant infrastructure layer to isolate workloads from one another for security reasons.
What is getting disrupted here is not the core building blocks that advanced cloud platforms provide, but how we’re putting together infrastructure building blocks for agility, efficiency, availability, heterogeneity etc. The patterns we’ve been using to arrive at these ilities are now becoming commodities. The likes of Kubernetes and Mesos are abstracting out the complexity involved in designing for these ilities. The era of commoditization of infrastructure patterns is finally here. The rewriting exercises that both CloudFoundry and OpenShift are going through in 2014 reflect this shift.
Let me start with one of the most basic patterns used to deploy stateless front end apps for scalability and availability. Here is an example topology.

This topology consists of several compute resources in a cluster behind a VIP attached to a load balancer or a proxy server deployed in two or more availability zones (coarse grained fault domains), and some kind of DNS based routing to send traffic to nodes in these clusters. You can scale this pattern by adding more nodes behind the VIP, and increase availability by spreading the resources across several availability zones. The larger the number of availability zones you use the less amount of spare capacity you would need to survive loss of any availability zone.
Most home-grown PaaS layers start by automating ways to provision and manage apps across such a topology. The pattern usually maximizes developer agility, availability and scalability. This pattern requires a service to provision compute resources, one to manage clusters of nodes behind VIPs, and another to manage DNS. You can automate the implementation of this pattern by making these three services extremely efficient. An orchestration service would help simplify the implementation.
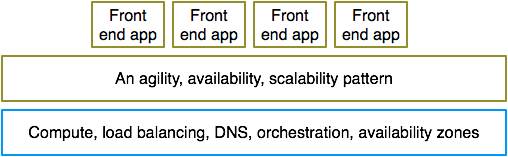
The bottom layer here consists of the building blocks needed to implement the pattern shown in middle layer. In fact, the first generation of cloud at eBay looked exactly like the above. The infrastructure layer in that cloud was built to suite the implementation of the above pattern.
Services like AWS CloudFormation and AWS CloudWatch make this topology resilient to failures and workload changes with auto-scaling. With the addition of such services to our build blocks layer, we can refine our pattern for resiliency.
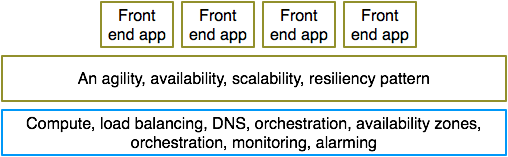
Kubernetes arrives at a similar outcome for containerized applications, with cAdvisor providing for monitoring. CloudFoundry’s Diego is treading along the same lines.
Consider Mesos for another example. It can help get the most work done out of a given fixed pool of compute resources by finely slicing and dicing compute and allocating to different types of workloads. You can, for instance, run front-end, batch, and Yarn with the help of Marathon, Aurora, and Myriad frameworks respectively on a single pool of compute resources. Depending on your security and data classification needs, you may need an underlying layer provide multi-tenancy with compute, network and storage isolation.
The general theme to notice here is a layered cake consisting of a layer of platforms enforcing certain patterns, utilizing a layer of foundational building blocks to implement those patterns.
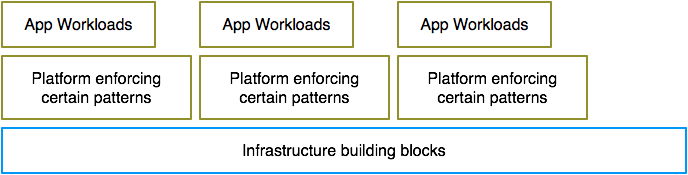
In essence, the complexity of dealing with raw infrastructure services, and that of implementing various patterns, is getting restructured for the better. As Mårten Mickos puts it in a recent Newstack article, “it may seem like you are removing the complexity but really it is just is pushing it somewhere else.” Layers help shuffle complexity better. By keeping the lower layers generic, we can let new patterns emerge.
An effective cloud platform needs both a strong layer of infrastructure building blocks, and platforms enforcing certain patterns. It is not a question of one versus the other. I’m not attempting to list the basic building blocks here, but a quick scan of AWS should give a hint of what the most common ones are. In fact without the core building blocks offered as services with 4 nines of availability, your infrastructure may remain as pets and not cattle. More about that latter.